
Figure.1
| PolarSPARC |
Exploring Kafka Streams :: Part 1
| Bhaskar S | 11/14/2021 |
Overview
The data and information driven world we live in currently, curious to know the amount of data generated per minute ???
Take a look at the following illustration to get some interesting insights about data:
There is an ever growing demand to process the various data events in real-time. Kafka Streams is an efficient, lightweight, and powerful Java based library for building fully distributed, elastic, fault tolerant, and resilient data processing applications that consume, enrich, transform, and distribute stream of data events from various data sources.
Installation and Setup
The setup will be on a Ubuntu 20.04 LTS based Linux desktop. Ensure Docker is installed and setup. Else, refer to the article Introduction to Docker for installation instructions.
Create directory structures called kafka/data, kafka/state, zk/data, and zk/logs under $HOME by executing the following commands:
$ cd $HOME
$ mkdir -p logs kafka/data kafka/state zk/data zk/logs
For our exploration, we will be downloading and using the official docker images confluentinc/cp-zookeeper:7.0.0 and confluentinc/cp-kafka:7.0.0.
To pull and download the latest docker image for confluentinc/cp-zookeeper:7.0.0, execute the following command:
$ docker pull confluentinc/cp-zookeeper:7.0.0
The following should be the typical output:
7.0.0: Pulling from confluentinc/cp-zookeeper dde93efae2ff: Pull complete 94249d6f79d2: Pull complete 7e1cc5bff18f: Pull complete 973ef4c3a700: Pull complete da964db55641: Pull complete d8ec445f296e: Pull complete 7d078f256245: Pull complete f6c5e254b763: Pull complete 78a035798c3d: Pull complete 7a00439c5fbc: Pull complete f359c308420d: Pull complete Digest: sha256:cd05266dabba8fdfd89c4a62804e69bbf3f0c0b0d0fb2fa56b74663d892c5d0c Status: Downloaded newer image for confluentinc/cp-zookeeper:7.0.0 docker.io/confluentinc/cp-zookeeper:7.0.0
Similarly, to pull and download the latest docker image for confluentinc/cp-kafka:4.0.0-3, execute the following command:
$ docker pull confluentinc/cp-kafka:7.0.0
The following should be the typical output:
7.0.0: Pulling from confluentinc/cp-kafka dde93efae2ff: Already exists 94249d6f79d2: Already exists 7e1cc5bff18f: Already exists 973ef4c3a700: Already exists da964db55641: Already exists d8ec445f296e: Already exists 7d078f256245: Already exists f6c5e254b763: Already exists 78a035798c3d: Already exists 5d6bcef4f3c5: Pull complete 885b4a9be813: Pull complete Digest: sha256:9b3f922f03bed5bab9cd62df8eaad7fd72d26a8b42d87bfcbde3905a4295ec25 Status: Downloaded newer image for confluentinc/cp-kafka:7.0.0 docker.io/confluentinc/cp-kafka:7.0.0
To create a docker bridge network called kafka-net, execute the following command:
$ docker network create kafka-net
The following should be the typical output:
0a4143ecbc5129db87ece41412e7aa48ee8a0dde1d44410ccee9b384841151dc
To list all the docker networks, execute the following command:
$ docker network ls
The following should be the typical output:
NETWORK ID NAME DRIVER SCOPE 476d0b039108 bridge bridge local a2f3d3c27f6d host host local 0a4143ecbc51 kafka-net bridge local eda0e0f33b97 none null local
To start an instance of ZooKeeper using docker, execute the following command:
$ docker run --rm --name cp-zk-dev --network kafka-net -e ZOOKEEPER_CLIENT_PORT=10001 -e ZOOKEEPER_TICK_TIME=2000 -u $(id -u $USER):$(id -g $USER) -v $HOME/zk/data:/var/lib/zookeeper/data -v $HOME/zk/logs:/var/lib/zookeeper/log confluentinc/cp-zookeeper:7.0.0
The following should be the typical output:
... SNIP ...
[2021-11-13 08:37:24,414] INFO zookeeper.enableEagerACLCheck = false (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.digest.enabled = true (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.closeSessionTxn.enabled = true (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.flushDelay=0 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.maxWriteQueuePollTime=0 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.maxBatchSize=1000 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,415] INFO zookeeper.intBufferStartingSizeBytes = 1024 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,416] INFO Weighed connection throttling is disabled (org.apache.zookeeper.server.BlueThrottle)
[2021-11-13 08:37:24,418] INFO minSessionTimeout set to 4000 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,418] INFO maxSessionTimeout set to 40000 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,419] INFO Response cache size is initialized with value 400. (org.apache.zookeeper.server.ResponseCache)
[2021-11-13 08:37:24,419] INFO Response cache size is initialized with value 400. (org.apache.zookeeper.server.ResponseCache)
[2021-11-13 08:37:24,420] INFO zookeeper.pathStats.slotCapacity = 60 (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,420] INFO zookeeper.pathStats.slotDuration = 15 (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,420] INFO zookeeper.pathStats.maxDepth = 6 (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,420] INFO zookeeper.pathStats.initialDelay = 5 (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,421] INFO zookeeper.pathStats.delay = 5 (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,421] INFO zookeeper.pathStats.enabled = false (org.apache.zookeeper.server.util.RequestPathMetricsCollector)
[2021-11-13 08:37:24,424] INFO The max bytes for all large requests are set to 104857600 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,424] INFO The large request threshold is set to -1 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,424] INFO Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 clientPortListenBacklog -1 datadir /var/lib/zookeeper/log/version-2 snapdir /var/lib/zookeeper/data/version-2 (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,453] INFO Logging initialized @743ms to org.eclipse.jetty.util.log.Slf4jLog (org.eclipse.jetty.util.log)
[2021-11-13 08:37:24,549] WARN o.e.j.s.ServletContextHandler@626abbd0{/,null,STOPPED} contextPath ends with /* (org.eclipse.jetty.server.handler.ContextHandler)
[2021-11-13 08:37:24,549] WARN Empty contextPath (org.eclipse.jetty.server.handler.ContextHandler)
[2021-11-13 08:37:24,573] INFO jetty-9.4.43.v20210629; built: 2021-06-30T11:07:22.254Z; git: 526006ecfa3af7f1a27ef3a288e2bef7ea9dd7e8; jvm 11.0.13+8-LTS (org.eclipse.jetty.server.Server)
[2021-11-13 08:37:24,604] INFO DefaultSessionIdManager workerName=node0 (org.eclipse.jetty.server.session)
[2021-11-13 08:37:24,604] INFO No SessionScavenger set, using defaults (org.eclipse.jetty.server.session)
[2021-11-13 08:37:24,605] INFO node0 Scavenging every 660000ms (org.eclipse.jetty.server.session)
... SNIP ...
[2021-11-13 08:37:24,632] INFO Started AdminServer on address 0.0.0.0, port 8080 and command URL /commands (org.apache.zookeeper.server.admin.JettyAdminServer)
... SNIP ...
[2021-11-13 08:37:24,658] INFO zookeeper.snapshotSizeFactor = 0.33 (org.apache.zookeeper.server.ZKDatabase)
[2021-11-13 08:37:24,658] INFO zookeeper.commitLogCount=500 (org.apache.zookeeper.server.ZKDatabase)
[2021-11-13 08:37:24,664] INFO zookeeper.snapshot.compression.method = CHECKED (org.apache.zookeeper.server.persistence.SnapStream)
[2021-11-13 08:37:24,664] INFO Snapshotting: 0x0 to /var/lib/zookeeper/data/version-2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
[2021-11-13 08:37:24,667] INFO Snapshot loaded in 8 ms, highest zxid is 0x0, digest is 1371985504 (org.apache.zookeeper.server.ZKDatabase)
[2021-11-13 08:37:24,667] INFO Snapshotting: 0x0 to /var/lib/zookeeper/data/version-2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
[2021-11-13 08:37:24,668] INFO Snapshot taken in 0 ms (org.apache.zookeeper.server.ZooKeeperServer)
[2021-11-13 08:37:24,677] INFO zookeeper.request_throttler.shutdownTimeout = 10000 (org.apache.zookeeper.server.RequestThrottler)
[2021-11-13 08:37:24,677] INFO PrepRequestProcessor (sid:0) started, reconfigEnabled=false (org.apache.zookeeper.server.PrepRequestProcessor)
[2021-11-13 08:37:24,697] INFO Using checkIntervalMs=60000 maxPerMinute=10000 maxNeverUsedIntervalMs=0 (org.apache.zookeeper.server.ContainerManager)
[2021-11-13 08:37:24,697] INFO ZooKeeper audit is disabled. (org.apache.zookeeper.audit.ZKAuditProvider)
The parameter ZOOKEEPER_CLIENT_PORT with a value of 10001 specifies the network port on which ZooKeeper is listening for client connections.
The parameter ZOOKEEPER_TICK_TIME with a value of 2000 specifies the length of a single clock tick (measured in milliseconds) used by ZooKeeper to listen for heartbeats and manage timeouts.
To start an instance of Kafka Broker using docker, execute the following command:
$ docker run --rm --name cp-kafka-dev --network kafka-net -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=cp-zk-dev:10001 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://cp-kafka-dev:9092,PLAINTEXT_HOST://localhost:20001 -e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 -e KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1 -p 20001:20001 -u $(id -u $USER):$(id -g $USER) -v $HOME/kafka/data:/var/lib/kafka/data confluentinc/cp-kafka:7.0.0
The following should be the typical output:
... SNIP ...
[2021-11-13 08:41:21,708] INFO [ThrottledChannelReaper-ControllerMutation]: Starting (kafka.server.ClientQuotaManager$ThrottledChannelReaper)
[2021-11-13 08:41:21,746] INFO Loading logs from log dirs ArraySeq(/var/lib/kafka/data) (kafka.log.LogManager)
[2021-11-13 08:41:21,752] INFO Skipping recovery for all logs in /var/lib/kafka/data since clean shutdown file was found (kafka.log.LogManager)
[2021-11-13 08:41:21,757] INFO Loaded 0 logs in 11ms. (kafka.log.LogManager)
[2021-11-13 08:41:21,757] INFO Starting log cleanup with a period of 300000 ms. (kafka.log.LogManager)
[2021-11-13 08:41:21,759] INFO Starting log flusher with a default period of 9223372036854775807 ms. (kafka.log.LogManager)
[2021-11-13 08:41:21,776] INFO Starting the log cleaner (kafka.log.LogCleaner)
[2021-11-13 08:41:21,821] INFO [kafka-log-cleaner-thread-0]: Starting (kafka.log.LogCleaner)
[2021-11-13 08:41:22,072] INFO [BrokerToControllerChannelManager broker=1 name=forwarding]: Starting (kafka.server.BrokerToControllerRequestThread)
[2021-11-13 08:41:22,202] INFO Updated connection-accept-rate max connection creation rate to 2147483647 (kafka.network.ConnectionQuotas)
[2021-11-13 08:41:22,205] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2021-11-13 08:41:22,234] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Created data-plane acceptor and processors for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2021-11-13 08:41:22,235] INFO Updated connection-accept-rate max connection creation rate to 2147483647 (kafka.network.ConnectionQuotas)
[2021-11-13 08:41:22,235] INFO Awaiting socket connections on 0.0.0.0:20001. (kafka.network.Acceptor)
[2021-11-13 08:41:22,242] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Created data-plane acceptor and processors for endpoint : ListenerName(PLAINTEXT_HOST) (kafka.network.SocketServer)
[2021-11-13 08:41:22,249] INFO [BrokerToControllerChannelManager broker=1 name=alterIsr]: Starting (kafka.server.BrokerToControllerRequestThread)
[2021-11-13 08:41:22,269] INFO [ExpirationReaper-1-Produce]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,269] INFO [ExpirationReaper-1-Fetch]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,270] INFO [ExpirationReaper-1-DeleteRecords]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,271] INFO [ExpirationReaper-1-ElectLeader]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,289] INFO [LogDirFailureHandler]: Starting (kafka.server.ReplicaManager$LogDirFailureHandler)
[2021-11-13 08:41:22,317] INFO Creating /brokers/ids/1 (is it secure? false) (kafka.zk.KafkaZkClient)
[2021-11-13 08:41:22,351] INFO Stat of the created znode at /brokers/ids/1 is: 27,27,1636792882338,1636792882338,1,0,0,72062224988176385,272,0,27
(kafka.zk.KafkaZkClient)
[2021-11-13 08:41:22,352] INFO Registered broker 1 at path /brokers/ids/1 with addresses: PLAINTEXT://cp-kafka-dev:9092,PLAINTEXT_HOST://localhost:20001, czxid (broker epoch): 27 (kafka.zk.KafkaZkClient)
[2021-11-13 08:41:22,413] INFO [ControllerEventThread controllerId=1] Starting (kafka.controller.ControllerEventManager$ControllerEventThread)
[2021-11-13 08:41:22,420] INFO [ExpirationReaper-1-topic]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,424] INFO [ExpirationReaper-1-Heartbeat]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,425] INFO [ExpirationReaper-1-Rebalance]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,435] INFO Successfully created /controller_epoch with initial epoch 0 (kafka.zk.KafkaZkClient)
[2021-11-13 08:41:22,442] INFO [GroupCoordinator 1]: Starting up. (kafka.coordinator.group.GroupCoordinator)
[2021-11-13 08:41:22,444] INFO [Controller id=1] 1 successfully elected as the controller. Epoch incremented to 1 and epoch zk version is now 1 (kafka.controller.KafkaController)
[2021-11-13 08:41:22,446] INFO [GroupCoordinator 1]: Startup complete. (kafka.coordinator.group.GroupCoordinator)
[2021-11-13 08:41:22,450] INFO [Controller id=1] Creating FeatureZNode at path: /feature with contents: FeatureZNode(Enabled,Features{}) (kafka.controller.KafkaController)
[2021-11-13 08:41:22,454] INFO Feature ZK node created at path: /feature (kafka.server.FinalizedFeatureChangeListener)
[2021-11-13 08:41:22,463] INFO [TransactionCoordinator id=1] Starting up. (kafka.coordinator.transaction.TransactionCoordinator)
[2021-11-13 08:41:22,470] INFO [Transaction Marker Channel Manager 1]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager)
[2021-11-13 08:41:22,470] INFO [TransactionCoordinator id=1] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator)
[2021-11-13 08:41:22,487] INFO Updated cache from existing <empty> to latest FinalizedFeaturesAndEpoch(features=Features{}, epoch=0). (kafka.server.FinalizedFeatureCache)
[2021-11-13 08:41:22,488] INFO [Controller id=1] Registering handlers (kafka.controller.KafkaController)
[2021-11-13 08:41:22,494] INFO [Controller id=1] Deleting log dir event notifications (kafka.controller.KafkaController)
[2021-11-13 08:41:22,498] INFO [Controller id=1] Deleting isr change notifications (kafka.controller.KafkaController)
[2021-11-13 08:41:22,500] INFO [ExpirationReaper-1-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-13 08:41:22,504] INFO [Controller id=1] Initializing controller context (kafka.controller.KafkaController)
[2021-11-13 08:41:22,515] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[2021-11-13 08:41:22,518] INFO [Controller id=1] Initialized broker epochs cache: HashMap(1 -> 27) (kafka.controller.KafkaController)
[2021-11-13 08:41:22,531] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Starting socket server acceptors and processors (kafka.network.SocketServer)
[2021-11-13 08:41:22,540] INFO [RequestSendThread controllerId=1] Starting (kafka.controller.RequestSendThread)
[2021-11-13 08:41:22,541] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Started data-plane acceptor and processor(s) for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2021-11-13 08:41:22,542] INFO [Controller id=1] Currently active brokers in the cluster: Set(1) (kafka.controller.KafkaController)
[2021-11-13 08:41:22,542] INFO [Controller id=1] Currently shutting brokers in the cluster: HashSet() (kafka.controller.KafkaController)
[2021-11-13 08:41:22,543] INFO [Controller id=1] Current list of topics in the cluster: HashSet() (kafka.controller.KafkaController)
[2021-11-13 08:41:22,543] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Started data-plane acceptor and processor(s) for endpoint : ListenerName(PLAINTEXT_HOST) (kafka.network.SocketServer)
[2021-11-13 08:41:22,543] INFO [Controller id=1] Fetching topic deletions in progress (kafka.controller.KafkaController)
[2021-11-13 08:41:22,544] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Started socket server acceptors and processors (kafka.network.SocketServer)
[2021-11-13 08:41:22,546] INFO [Controller id=1] List of topics to be deleted: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,547] INFO [Controller id=1] List of topics ineligible for deletion: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,547] INFO [Controller id=1] Initializing topic deletion manager (kafka.controller.KafkaController)
[2021-11-13 08:41:22,548] INFO [Topic Deletion Manager 1] Initializing manager with initial deletions: Set(), initial ineligible deletions: HashSet() (kafka.controller.TopicDeletionManager)
[2021-11-13 08:41:22,549] INFO [Controller id=1] Sending update metadata request (kafka.controller.KafkaController)
[2021-11-13 08:41:22,550] INFO Kafka version: 7.0.0-ccs (org.apache.kafka.common.utils.AppInfoParser)
[2021-11-13 08:41:22,550] INFO Kafka commitId: c6d7e3013b411760 (org.apache.kafka.common.utils.AppInfoParser)
[2021-11-13 08:41:22,550] INFO Kafka startTimeMs: 1636792882544 (org.apache.kafka.common.utils.AppInfoParser)
[2021-11-13 08:41:22,552] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
[2021-11-13 08:41:22,553] INFO [Controller id=1 epoch=1] Sending UpdateMetadata request to brokers HashSet(1) for 0 partitions (state.change.logger)
[2021-11-13 08:41:22,561] INFO [ReplicaStateMachine controllerId=1] Initializing replica state (kafka.controller.ZkReplicaStateMachine)
[2021-11-13 08:41:22,563] INFO [ReplicaStateMachine controllerId=1] Triggering online replica state changes (kafka.controller.ZkReplicaStateMachine)
[2021-11-13 08:41:22,568] INFO [ReplicaStateMachine controllerId=1] Triggering offline replica state changes (kafka.controller.ZkReplicaStateMachine)
[2021-11-13 08:41:22,570] INFO [PartitionStateMachine controllerId=1] Initializing partition state (kafka.controller.ZkPartitionStateMachine)
[2021-11-13 08:41:22,570] INFO [RequestSendThread controllerId=1] Controller 1 connected to cp-kafka-dev:9092 (id: 1 rack: null) for sending state change requests (kafka.controller.RequestSendThread)
[2021-11-13 08:41:22,571] INFO [PartitionStateMachine controllerId=1] Triggering online partition state changes (kafka.controller.ZkPartitionStateMachine)
[2021-11-13 08:41:22,575] INFO [Controller id=1] Ready to serve as the new controller with epoch 1 (kafka.controller.KafkaController)
[2021-11-13 08:41:22,581] INFO [Controller id=1] Partitions undergoing preferred replica election: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,582] INFO [Controller id=1] Partitions that completed preferred replica election: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,583] INFO [Controller id=1] Skipping preferred replica election for partitions due to topic deletion: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,583] INFO [Controller id=1] Resuming preferred replica election for partitions: (kafka.controller.KafkaController)
[2021-11-13 08:41:22,585] INFO [Controller id=1] Starting replica leader election (PREFERRED) for partitions triggered by ZkTriggered (kafka.controller.KafkaController)
[2021-11-13 08:41:22,600] INFO [Controller id=1] Starting the controller scheduler (kafka.controller.KafkaController)
[2021-11-13 08:41:22,653] INFO [BrokerToControllerChannelManager broker=1 name=alterIsr]: Recorded new controller, from now on will use broker cp-kafka-dev:9092 (id: 1 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2021-11-13 08:41:22,682] INFO [BrokerToControllerChannelManager broker=1 name=forwarding]: Recorded new controller, from now on will use broker cp-kafka-dev:9092 (id: 1 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2021-11-13 08:41:27,601] INFO [Controller id=1] Processing automatic preferred replica leader election (kafka.controller.KafkaController)
The parameter KAFKA_BROKER_ID with a value of 1 specifies the unique identifier associated with a Kafka Broker.
The parameter KAFKA_ZOOKEEPER_CONNECT with a value of cp-zk-dev:10001 specifies the host:port of the ZooKeeper instance to connect to.
The parameter KAFKA_LISTENER_SECURITY_PROTOCOL_MAP with a value of PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT specifies the security protocols to use.
The parameter KAFKA_ADVERTISED_LISTENERS with a value of PLAINTEXT://cp-kafka-dev:9092,PLAINTEXT_HOST://localhost:20001 specifies a comma-separated list of Kafka Brokers with their host:port values. This is the host:port that Producer(s) and Consumer(s) use to connect to the Kafka Broker.
The parameter KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR with a value of 1 is needed for a single-node Kafka Broker.
The parameter KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR with a value of 1 is needed for a single-node Kafka Broker.
At this point a single node Kafka Broker with a ZooKeeper must be up and running.
To check the running docker containers, execute the following command:
$ docker ps
The following should be the typical output:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7b1a54d6a38f confluentinc/cp-kafka:7.0.0 "/etc/confluent/dock…" 24 minutes ago Up 24 minutes 9092/tcp, 0.0.0.0:20001->20001/tcp, :::20001->20001/tcp cp-kafka-dev 4dcfa528da54 confluentinc/cp-zookeeper:7.0.0 "/etc/confluent/dock…" 28 minutes ago Up 28 minutes 2181/tcp, 2888/tcp, 3888/tcp cp-zk-dev
Ensure at least Java 11 or above is installed and setup. Also, ensure Apache Maven is installed and setup.
To setup the root Java directory structure for the demonstrations in this article, execute the following commands:
$ cd $HOME
$ mkdir -p $HOME/java/KafkaStreams
$ cd $HOME/java/KafkaStreams
$ mkdir -p src/main/java src/main/resources
The following is the listing for the slf4j-simple logger properties file simplelogger.properties located in the directory src/main/resources:
# ### SLF4J Simple Logger properties # org.slf4j.simpleLogger.defaultLogLevel=info org.slf4j.simpleLogger.showDateTime=true org.slf4j.simpleLogger.dateTimeFormat=yyyy-MM-dd HH:mm:ss:SSS org.slf4j.simpleLogger.showThreadName=true
The following is the listing for the parent Maven project file pom.xml that will be located at $HOME/java/KafkaStreams:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.polarsparc.kstreams</groupId>
<artifactId>KafkaStreams</artifactId>
<packaging>pom</packaging>
<version>1.0</version>
<modules>
</modules>
<properties>
<compiler.source>17</compiler.source>
<compiler.target>17</compiler.target>
<kafka.streams.version>3.0.0</kafka.streams.version>
<slf4j.version>1.7.32</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.streams.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${compiler.source}</source>
<target>${compiler.target}</target>
</configuration>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${compiler.source}</source>
<target>${compiler.target}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Kafka Streams Overview
As indicated earlier, Kafka Streams is just a library that enables one to process data records (also referred to as events) on a per event basis. Per event means real time processing as the data records (events) arrive. In other words, it is a continuous stream of data records (events).
The data processing in Kafka Streams involves a series of steps, such as, inputs, processing stages (filtering, transformation, branching, aggregation, etc.), and outputs, which is represented as a directed acyclic graph.
The following is a sample illustration of a typical Kafka Streams data pipeline:
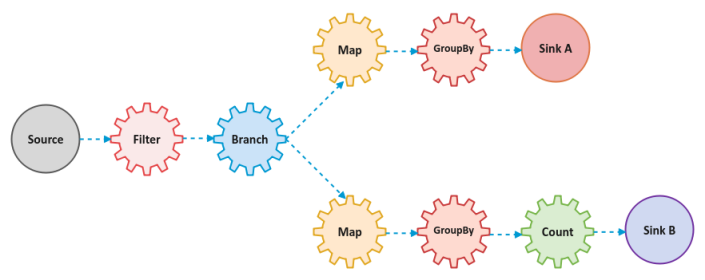
The following are some of the terminology used in Kafka Streams:
Stream :: an unbounded, continuously sequence of immutable data events, that is fully ordered, replayable, and fault tolerant
Stream Processor :: a processing step in the data process graph
Source Processor :: a special Stream Processor that does not have predecessors and consumes events from a Kafka Topic
Sink Processor :: a special StreamProcessor that does not have any children and sends events to a Kafka Topic
Topology :: a graph of Processors that are chained together to perform the desired data processing
Stateless :: the result of a transformation depends only on the current data event being processed with no recollection of past events
Stateful :: the result of a transformation depends on the current data event plus the previous state
Note that Kafka Streams uses a depth-first strategy when processing events. When a new event is received, it is processed by each of the Stream Processors in the topology before proceeding to another event in the data pipeline.
Hands-on with Kafka Streams
First, we will create a Common module to house the necessary utility class(es) that will be used across the different sample applications in this series.
To setup the Java directory structure for the Common module, execute the following commands:
$ cd $HOME/java/KafkaStreams
$ mkdir -p $HOME/java/KafkaStreams/Common
$ mkdir -p Common/src/main/java Common/src/main/resources Common/target
$ mkdir -p Common/src/main/resources/com/polarsparc/kstreams
$ cd $HOME/java/KafkaStreams/Common
The following is the listing for the Maven project file pom.xml that will be used:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>KafkaStreams</artifactId>
<groupId>com.polarsparc.kstreams</groupId>
<version>1.0</version>
</parent>
<artifactId>Common</artifactId>
<version>1.0</version>
</project>
We need to modify the <modules> section in the parent pom.xml to include the Common module as shown below:
<modules> <module>Common</module> </modules>
The following is the Java utility class that encapsulates the Kafka consumer configuration options:
/*
* Name: Kafka Consumer Configuration
* Author: Bhaskar S
* Date: 11/10/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import java.util.Properties;
public final class KafkaConsumerConfig {
public static Properties kafkaConfigurationOne(String appId) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, appId);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:20001");
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return config;
}
private KafkaConsumerConfig() {}
}
Let us explain and understand some of the configuration properties used in the code shown above.
The class org.apache.kafka.streams.StreamsConfig encapsulates the various Kafka Streams configuration options as java.lang.String constants.
The class org.apache.kafka.clients.consumer.ConsumerConfig encapsulates the various Kafka consumer configuration options as java.lang.String constants.
The property StreamsConfig.APPLICATION_ID_CONFIG allows one to specify a unique identifier for the streams processing application. This is used by Kafka to track the state of the application.
The property StreamsConfig.BOOTSTRAP_SERVERS_CONFIG allows one to specify a comma-separated list of Kafka brokers as host:port pairs. In our case, we have one Kafka broker at localhost:20001.
The property ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG allows one to control when to commit the cuurent consumer offset. By default, it automatically commits at periodic intervals. Setting it to 'false' means giving the consumer to control when to commit.
The property ConsumerConfig.AUTO_OFFSET_RESET_CONFIG allows one to specify the action to take when the Kafka consumer is started for the very first time (there is no committed offset(s) for the consumer). In our case, we have specified a value of earliest indicating we want to consume messages from the beginning.
The property ConsumerConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG allows one to specify the default serializer/deserializer class for the key associated with the messages to be consumed. In our case, we are using a Java 'String' serializer/deserializer.
The property ConsumerConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG allows one to specify the default serializer/deserializer class for the data value associated with the messages to be consumed. In our case, we are using a Java 'String' serializer/deserializer.
We need to compile and deploy the Common module so that the other Java modules can use it. To do that, open a terminal window and run the following commands:
$ $HOME/java/KafkaStreams/Common
$ mvn clean install
First Application
In the First module, we will demonstrate two Kafka Streams applications - one will be a stateless and the other will be stateful. In both the cases, the application will consume data events from the Kafka topic survey-event and display some output based on some processing. Each event will be in the form user:language, where 'user' is the key and 'language' is the value. The data events allow one to do a quick survey of a user's preferred programming language from a selected set.
To setup the Java directory structure for the First application, execute the following commands:
$ cd $HOME/java/KafkaStreams
$ mkdir -p $HOME/java/KafkaStreams/First
$ mkdir -p First/src/main/java First/src/main/resources First/target
$ mkdir -p First/src/main/java/com/polarsparc/kstreams
$ cd $HOME/java/KafkaStreams/First
The following is the listing for the Maven project file pom.xml that will be used:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>KafkaStreams</artifactId>
<groupId>com.polarsparc.kstreams</groupId>
<version>1.0</version>
</parent>
<artifactId>First</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<artifactId>Common</artifactId>
<groupId>com.polarsparc.kstreams</groupId>
<version>1.0</version>
</dependency>
</dependencies>
</project>
We need to modify the <modules> section in the parent pom.xml to include the First module as shown below:
<modules> <module>Common</module> <module>First</module> </modules>
The following is the Java based STATELESS Kafka Streams application that consumes and processes events from the Kafka topic survey-event:
/*
* Name: Survey Events (Stateless)
* Author: Bhaskar S
* Date: 11/10/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Set;
public class SurveyEventsStateless {
private static final String SURVEY_EVENT = "survey-event";
public static void main(String[] args) {
Logger log = LoggerFactory.getLogger(SurveyEventsStateless.class.getName());
Set<String> langSet = Set.copyOf(Arrays.asList("Go", "Java", "Python"));
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream(SURVEY_EVENT);
stream.filter((user, lang) -> langSet.contains(lang))
.map((user, lang) -> KeyValue.pair(lang.toLowerCase(), user.toLowerCase()))
.foreach((lang, user) -> log.info(String.format("%s - %s", lang, user)));
KafkaStreams streams = new KafkaStreams(builder.build(),
KafkaConsumerConfig.kafkaConfigurationOne("survey-event-1"));
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
The code from Listing.2 above needs some explanation:
The class org.apache.kafka.streams.StreamsBuilder allows one to use the high-level Kafka Streams domain specific language (DSL) interface to specify the streams topology.
The interface org.apache.kafka.streams.kstream.KStream is an abstraction of a partitioned, unbounded stream of data events, in which data is represented using insert semantics, similar to an append-only log.
The DSL method builder.stream(TOPIC) allows one to create an instance of a KStream object for the specified Kafka TOPIC. The stream uses the default key and value serializer/deserializer.
The method filter(PREDICATE) returns a KStream object that consists of data events that satisfy the given PREDICATE function.
The DSL method map(MAPPER) allows one to create an instance of a KStream object with each incoming data event transformed to a new data event using the given MAPPER function.
The DSL method foreach(ACTOR) allows one to apply the given ACTOR function on each of the incoming data events. This is a Sink Processor.
The class org.apache.kafka.streams.KafkaStreams allows one to create a Kafka client that continuously consumes data events from the Kafka topic associated with the stream and performs all the DSL operations as defined in the topology.
Before we can start the application, we need to create the desired Kafka topic. To create the Kafka topic survey-event using docker, execute the following command:
docker run --rm --net=host confluentinc/cp-kafka:7.0.0 kafka-topics --create --topic survey-event --partitions 1 --replication-factor 1 --if-not-exists --bootstrap-server localhost:20001
The following should be the typical output:
Created topic survey-event.
To execute the code from Listing.2, open a terminal window and run the following commands:
$ $HOME/java/KafkaStreams/First
$ mvn clean compile
$ mvn exec:java -Dexec.mainClass="com.polarsparc.kstreams.SurveyEventsStateless"
The following would be the typical output:
... SNIP ...
[com.polarsparc.kstreams.SurveyEventsStateless.main()] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka version: 3.0.0
[com.polarsparc.kstreams.SurveyEventsStateless.main()] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka commitId: 8cb0a5e9d3441962
[com.polarsparc.kstreams.SurveyEventsStateless.main()] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka startTimeMs: 1636912237452
[com.polarsparc.kstreams.SurveyEventsStateless.main()] INFO org.apache.kafka.streams.KafkaStreams - stream-client [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683] State transition from CREATED to REBALANCING
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] Starting
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] State transition from CREATED to STARTING
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Subscribed to topic(s): survey-event
[kafka-producer-network-thread | survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-producer] INFO org.apache.kafka.clients.Metadata - [Producer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-producer] Cluster ID: nHWTpcoETziH-8m1PoIEtQ
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] Processed 0 total records, ran 0 punctuators, and committed 0 total tasks since the last update
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.Metadata - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Cluster ID: nHWTpcoETziH-8m1PoIEtQ
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Discovered group coordinator localhost:20001 (id: 2147483646 rack: null)
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] (Re-)joining group
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Request joining group due to: need to re-join with the given member-id
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] (Re-)joining group
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Successfully joined group with generation Generation{generationId=2, memberId='survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer-49c9dc44-6d71-4aa2-a668-2da4b72c2d77', protocol='stream'}
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamsPartitionAssignor - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer] All members participating in this rebalance:
fdb44b01-4017-41f9-b81a-2c5768cef683: [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer-49c9dc44-6d71-4aa2-a668-2da4b72c2d77].
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.assignment.HighAvailabilityTaskAssignor - Decided on assignment: {fdb44b01-4017-41f9-b81a-2c5768cef683=[activeTasks: ([0_0]) standbyTasks: ([]) prevActiveTasks: ([]) prevStandbyTasks: ([]) changelogOffsetTotalsByTask: ([]) taskLagTotals: ([]) capacity: 1 assigned: 1]} with no followup probing rebalance.
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamsPartitionAssignor - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer] Assigned tasks [0_0] including stateful [] to clients as:
fdb44b01-4017-41f9-b81a-2c5768cef683=[activeTasks: ([0_0]) standbyTasks: ([])].
... SNIP ...
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamsPartitionAssignor - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer] Finished stable assignment of tasks, no followup rebalances required.
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Finished assignment for group at generation 2: {survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer-49c9dc44-6d71-4aa2-a668-2da4b72c2d77=Assignment(partitions=[survey-event-0], userDataSize=52)}
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Successfully synced group in generation Generation{generationId=2, memberId='survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer-49c9dc44-6d71-4aa2-a668-2da4b72c2d77', protocol='stream'}
... SNIP ...
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Notifying assignor about the new Assignment(partitions=[survey-event-0], userDataSize=52)
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamsPartitionAssignor - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer] No followup rebalance was requested, resetting the rebalance schedule.
... SNIP ...
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Adding newly assigned partitions: survey-event-0
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] State transition from STARTING to PARTITIONS_ASSIGNED
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamTask - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] task [0_0] Initialized
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Found no committed offset for partition survey-event-0
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamTask - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] task [0_0] Restored and ready to run
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] Restoration took 12 ms for all tasks [0_0]
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.KafkaStreams - stream-client [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683] State transition from REBALANCING to RUNNING
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Requesting the log end offset for survey-event-0 in order to compute lag
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Found no committed offset for partition survey-event-0
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.SubscriptionState - [Consumer clientId=survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1-consumer, groupId=survey-event-1] Resetting offset for partition survey-event-0 to position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[localhost:20001 (id: 1 rack: null)], epoch=0}}.
We need to publish some events to the Kafka topic survey-event. Open a terminal window and run the Kafka console publisher using the following command:
$ docker run -it --rm --net=host confluentinc/cp-kafka:7.0.0 kafka-console-producer --bootstrap-server localhost:20001 --property key.separator=, --property parse.key=true --request-required-acks 1 --topic survey-event
The prompt will change to >.
Enter the following events:
>Alice,Go
>Bob,Java
>Charlie,Python
>Eva,Rust
>Frank,Java
>George,Python
>Harry,Python
The following would be the additional output in the terminal running the application from Listing.2 above:
[survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - go - alice [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] Processed 1 total records, ran 0 punctuators, and committed 0 total tasks since the last update [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - java - bob [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - python - charlie [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - java - frank [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - python - george [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateless - python - harry [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [survey-event-1-fdb44b01-4017-41f9-b81a-2c5768cef683-StreamThread-1] Processed 6 total records, ran 0 punctuators, and committed 3 total tasks since the last update
We have successfully demonstrated the Java based STATELESS Kafka Streams application.
The following is the Java based STATEFUL Kafka Streams application that consumes and processes events from the Kafka topic survey-event:
/*
* Name: Survey Events (Stateful)
* Author: Bhaskar S
* Date: 11/10/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Set;
public class SurveyEventsStateful {
private static final String SURVEY_EVENT = "survey-event";
public static void main(String[] args) {
Logger log = LoggerFactory.getLogger(SurveyEventsStateful.class.getName());
Set<String> langSet = Set.copyOf(Arrays.asList("Go", "Java", "Python"));
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> input = builder.stream(SURVEY_EVENT);
KTable<String, Long> table = input.filter((user, lang) -> langSet.contains(lang))
.map((user, lang) -> KeyValue.pair(lang.toLowerCase(), user.toLowerCase()))
.groupByKey()
.count();
table.toStream()
.foreach((lang, count) -> log.info(String.format("%s - %d", lang, count)));
KafkaStreams streams = new KafkaStreams(builder.build(),
KafkaConsumerConfig.kafkaConfigurationOne("survey-event-2"));
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
The code from Listing.3 above needs some explanation:
The interface org.apache.kafka.streams.kstream.KTable is an abstraction of a partitioned table, in which data is represented using update semantics, similar to a database table (upsert on non-null values and delete on null values).
The method groupByKey() returns a stream object that groups data events belonging to the same key.
The DSL method count() returns a KTable object that allows one to count all the data events belonging to the same key.
The DSL method toStream() converts a KTable object to a KStream object.
To execute the code from Listing.3, open a terminal window and run the following commands:
$ $HOME/java/KafkaStreams/First
$ mvn clean compile
$ mvn exec:java -Dexec.mainClass="com.polarsparc.kstreams.SurveyEventsStateful"
The following would be the typical output:
[survey-event-2-37bfbfc6-6271-4123-8fef-2dc85bb96df3-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateful - go - 1 [survey-event-2-37bfbfc6-6271-4123-8fef-2dc85bb96df3-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateful - java - 2 [survey-event-2-37bfbfc6-6271-4123-8fef-2dc85bb96df3-StreamThread-1] INFO com.polarsparc.kstreams.SurveyEventsStateful - python - 3
We have successfully demonstrated the Java based STATEFUL Kafka Streams application.
References