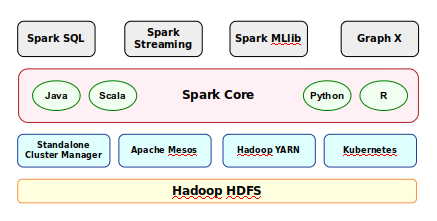
The installation will be performed on a Ubuntu 18.04 based desktop.
Download a stable version of Spark (2.4.4 at the time of this article) from the project site located at the
URL spark.apache.org.
We choose to download the Spark version 2.4.4 (pre-built for Hadoop 2.7) for this setup.
The following diagram illustrates the download from the Apache Spark site
spark.apache.org:
-
Ensure Java SE 8 is installed. In our case, OpenJDK 8 (Java SE 8) was installed in
the directory /usr/lib/jvm/java-8-openjdk-amd64
☠ ATTENTION ☠
Spark 2.4.4 will only work with JDK 8
-
Ensure Python 3.7 or above is installed. To make it easy and simple, we choose the open-source
Anaconda Python 3
distribution, which includes all the necessary Python packages.
Download the Python 3.7 version of the Anaconda distribution.
Extract and install the downloaded Anaconda Python 3 archive to a directory, say,
/home/polarsparc/Programs/anaconda3.
-
Extract the downloaded spark-2.4.4-bin-hadoop2.7.tgz file into a desired directory
(say /home/polarsparc/Programs/spark-2.4.4)
The following diagram illustrates the contents of the directory /home/polarsparc/Programs/spark-2.4.4 after extraction:
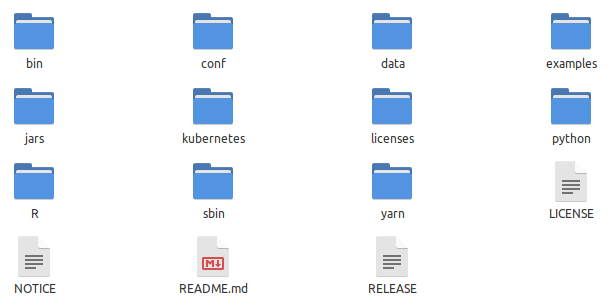
Spark 2.4.4 Extract
-
Open a terminal and change the working directory to /home/polarsparc/Programs
Create a shell (.sh) file called env.sh with the following lines:
export SPARK_HOME=/home/polarsparc/Programs/spark-2.4.4
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_CLASSPATH=`echo $SPARK_HOME/jars/* | sed 's/ /:/g'`
-
Change the working directory to /home/polarsparc
Source the environment variables in the file env.sh, by typing the following command:
-
In the terminal window, execute the following command to launch the Python Spark shell:
pyspark --master local[1]
The option local[1] indicates that we want to execute Spark core and the Python
shell in a standalone local mode without any cluster manager. This mode is useful
during development and testing.
The following should be the typical output:
Output.1
Python 3.7.4 (default, Aug 13 2019, 20:35:49)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
19/09/29 12:41:58 WARN Utils: Your hostname, polarsparc resolves to a loopback address: 127.0.1.1; using 192.168.1.179 instead (on interface enp6s0)
19/09/29 12:41:58 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
19/09/29 12:41:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Python version 3.7.4 (default, Aug 13 2019 20:35:49)
SparkSession available as 'spark'.
>>>
-
Exit the Python Spark shell, by typing the following command:
-
In the terminal window, change to the directory /home/polarsparc/Programs/spark-2.4.4/conf
and execute the following commands:
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
Delete all the contents of the file spark-env.sh under the directory
/home/polarsparc/Programs/spark-2.4.4/conf and add the following lines (don't worry about the details for now):
SPARK_IDENT_STRING=MySpark
SPARK_DRIVER_MEMORY=2g
SPARK_EXECUTOR_CORES=1
SPARK_EXECUTOR_MEMORY=1g
SPARK_LOCAL_IP=localhost
SPARK_LOCAL_DIRS=$SPARK_HOME/work
SPARK_MASTER_HOST=localhost
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_DIR=$SPARK_HOME/work
-
Change the working directory to /home/polarsparc
Let us once again try to re-launch the Python Spark shell in the terminal window:
pyspark --master local[1]
The following will be the typical output:
Output.2
Python 3.7.4 (default, Aug 13 2019, 20:35:49)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
19/09/29 13:46:00 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Python version 3.7.4 (default, Aug 13 2019 20:35:49)
SparkSession available as 'spark'.
>>>
-
Let us go ahead and try the following command from the Python Spark shell (dont worry about the details for now):
lines = sc.textFile('./Programs/spark-2.4.4/README.md')
-
If all goes well, there will be *NO* output
Let us go ahead and try the following command from the Python Spark shell (dont worry about the details for now):
The following will be the typical output:
-
BINGO - the Python Spark shell works !!!
The following diagram illustrates the screenshot for the Spark UI that can be accessed at
http://localhost:4040:
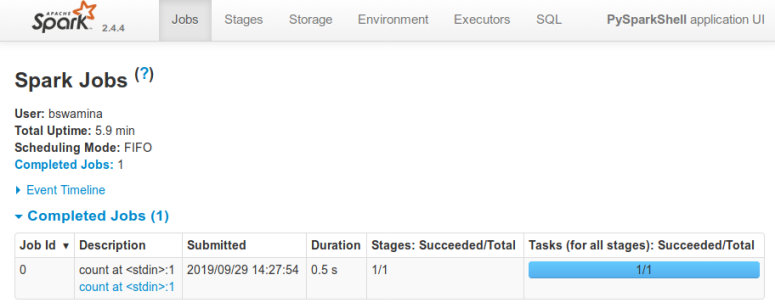
Spark 2.4.4 UI
-
Exit the Python Spark shell, by typing the following command:
-
We need to configure pyspark to use Jupyter Notebook.
In the terminal window, change the working directory to /home/polarsparc/Programs
Modify the file called env.sh to append the following lines:
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
-
Change the working directory to /home/polarsparc
Source the environment variables in the file env.sh, by typing the following command:
-
Create a new directory called /home/polarsparc/Projects/Python/Notebooks/Spark
and change to that directory.
In the terminal window, once again execute the following command to launch the Python Spark shell:
pyspark --master local[1]
The following will be the typical output:
Output.4
[I 15:06:53.372 NotebookApp] JupyterLab extension loaded from /home/polarsparc/Programs/anaconda3/lib/python3.7/site-packages/jupyterlab
[I 15:06:53.372 NotebookApp] JupyterLab application directory is /home/polarsparc/Programs/anaconda3/share/jupyter/lab
[I 15:06:53.374 NotebookApp] Serving notebooks from local directory: /home/polarsparc/Projects/Python/Notebooks/Spark
[I 15:06:53.374 NotebookApp] The Jupyter Notebook is running at:
[I 15:06:53.374 NotebookApp] http://localhost:8888/?token=df6db1202f8ff61f6a6b74081153f273ba47aef0d9597332
[I 15:06:53.374 NotebookApp] or http://127.0.0.1:8888/?token=df6db1202f8ff61f6a6b74081153f273ba47aef0d9597332
[I 15:06:53.374 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 15:06:53.430 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/polarsparc/.local/share/jupyter/runtime/nbserver-23473-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=df6db1202f8ff61f6a6b74081153f273ba47aef0d9597332
or http://127.0.0.1:8888/?token=df6db1202f8ff61f6a6b74081153f273ba47aef0d9597332
This will also launch a new browser window for the Jupyter notebook. The following diagram illustrates the
screenshot for the Jupyter notebook:
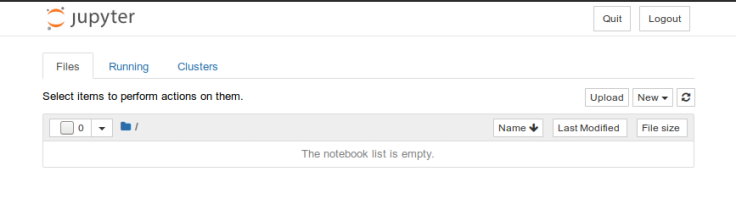
Jupyter Notebook