Hadoop Quick Notes :: Part - 2
In Part-1
we laid out the steps to install and setup a 3-node Hadoop
1.x cluster.
Now, we will actually start the Hadoop
cluster into action.
On hadoop-master, open a command
terminal window and issue the following command:
The following Figure-1 illustrates the execution of the above command
in the terminal window:
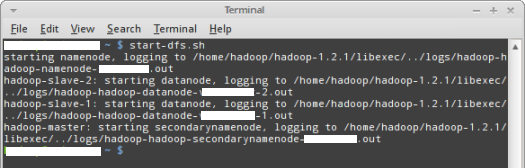
Figure-1
Next, issue the following command:
The following Figure-2 illustrates the execution of the above command
in the terminal window:
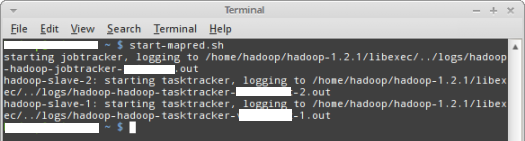
Figure-2
To verify all the necessary processes are started, issue the following
command:
The output of the above command should look like the one from Figure-3
below:
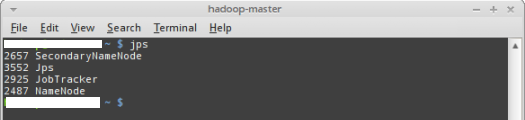
Figure-3
On hadoop-slave-1 (or hadoop-slave-2),
open a command terminal window and issue the following command:
The output of the above command should look like the one from Figure-4
below:

Figure-4
The following diagram in Figure-5 illustrates our 3-node Hadoop
cluster:
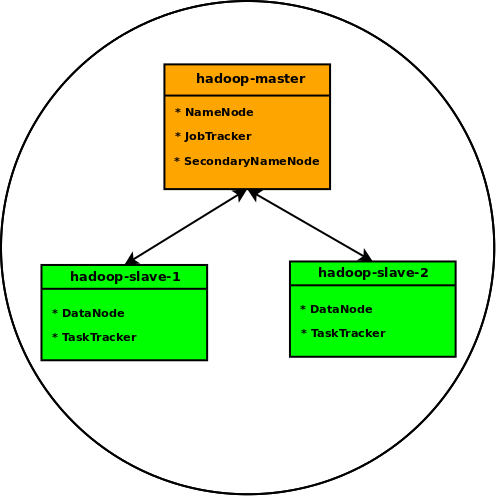
Figure-5
In this section we will elaborate on the core modules and components of
Hadoop.
The core of Hadoop is made up of the
following two modules:
Hands-on with Hadoop HDFS
In the following paragraphs we will continue to explore HDFS commands
using the hadoop shell.
To list all the commands supported by the hadoop
shell, execute the following command:
The following will be the output:
Output-1
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
datanode run a DFS datanode
dfsadmin run a DFS admin client
mradmin run a Map-Reduce admin client
fsck run a DFS filesystem checking utility
fs run a generic filesystem user client
balancer run a cluster balancing utility
oiv apply the offline fsimage viewer to an fsimage
fetchdt fetch a delegation token from the NameNode
jobtracker run the MapReduce job Tracker node
pipes run a Pipes job
tasktracker run a MapReduce task Tracker node
historyserver run job history servers as a standalone daemon
job manipulate MapReduce jobs
queue get information regarding JobQueues
version print the version
jar <jar> run a jar file
distcp <srcurl> <desturl> copy file or directories recursively
distcp2 <srcurl> <desturl> DistCp version 2
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
To use HDFS, we will mostly use the fs
command.
To list all the operations supported by the hadoop
fs command, execute the following command:
The following will be the output:
Output-2
hadoop fs is the command to execute fs commands. The full syntax is:
hadoop fs [-fs <local | file system URI>] [-conf <configuration file>]
[-D <property=value>] [-ls <path>] [-lsr <path>] [-du <path>]
[-dus <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <src>]
[-rmr [-skipTrash] <src>] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>]
[-moveFromLocal <localsrc> ... <dst>] [-get [-ignoreCrc] [-crc] <src> <localdst>
[-getmerge <src> <localdst> [addnl]] [-cat <src>]
[-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>] [-moveToLocal <src> <localdst>]
[-mkdir <path>] [-report] [-setrep [-R] [-w] <rep> <path/file>]
[-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>]
[-tail [-f] <path>] [-text <path>]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-chgrp [-R] GROUP PATH...]
[-count[-q] <path>]
[-help [cmd]]
-fs [local | <file system URI>]: Specify the file system to use.
If not specified, the current configuration is used,
taken from the following, in increasing precedence:
core-default.xml inside the hadoop jar file
core-site.xml in $HADOOP_CONF_DIR
'local' means use the local file system as your DFS.
<file system URI> specifies a particular file system to
contact. This argument is optional but if used must appear
appear first on the command line. Exactly one additional
argument must be specified.
-ls <path>: List the contents that match the specified file pattern. If
path is not specified, the contents of /user/<currentUser>
will be listed. Directory entries are of the form
dirName (full path) <dir>
and file entries are of the form
fileName(full path) <r n> size
where n is the number of replicas specified for the file
and size is the size of the file, in bytes.
-lsr <path>: Recursively list the contents that match the specified
file pattern. Behaves very similarly to hadoop fs -ls,
except that the data is shown for all the entries in the
subtree.
-du <path>: Show the amount of space, in bytes, used by the files that
match the specified file pattern. Equivalent to the unix
command "du -sb <path>/*" in case of a directory,
and to "du -b <path>" in case of a file.
The output is in the form
name(full path) size (in bytes)
-dus <path>: Show the amount of space, in bytes, used by the files that
match the specified file pattern. Equivalent to the unix
command "du -sb" The output is in the form
name(full path) size (in bytes)
-mv <src> <dst>: Move files that match the specified file pattern <src>
to a destination <dst>. When moving multiple files, the
destination must be a directory.
-cp <src> <dst>: Copy files that match the file pattern <src> to a
destination. When copying multiple files, the destination
must be a directory.
-rm [-skipTrash] <src>: Delete all files that match the specified file pattern.
Equivalent to the Unix command "rm <src>"
-skipTrash option bypasses trash, if enabled, and immediately
deletes <src>
-rmr [-skipTrash] <src>: Remove all directories which match the specified file
pattern. Equivalent to the Unix command "rm -rf <src>"
-skipTrash option bypasses trash, if enabled, and immediately deletes <src>
-put <localsrc> ... <dst>: Copy files from the local file system
into fs.
-copyFromLocal <localsrc> ... <dst>: Identical to the -put command.
-moveFromLocal <localsrc> ... <dst>: Same as -put, except that the source is
deleted after it's copied.
-get [-ignoreCrc] [-crc] <src> <localdst>: Copy files that match the file pattern <src>
to the local name. <src> is kept. When copying mutiple,
files, the destination must be a directory.
-getmerge <src> <localdst>: Get all the files in the directories that
match the source file pattern and merge and sort them to only
one file on local fs. <src> is kept.
-cat <src>: Fetch all files that match the file pattern <src>
and display their content on stdout.
-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>: Identical to the -get command.
-moveToLocal <src> <localdst>: Not implemented yet
-mkdir <path>: Create a directory in specified location.
-setrep [-R] [-w] <rep> <path/file>: Set the replication level of a file.
The -R flag requests a recursive change of replication level
for an entire tree.
-tail [-f] <file>: Show the last 1KB of the file.
The -f option shows apended data as the file grows.
-touchz <path>: Write a timestamp in yyyy-MM-dd HH:mm:ss format
in a file at <path>. An error is returned if the file exists with non-zero length
-test -[ezd] <path>: If file { exists, has zero length, is a directory
then return 0, else return 1.
-text <src>: Takes a source file and outputs the file in text format.
The allowed formats are zip and TextRecordInputStream.
-stat [format] <path>: Print statistics about the file/directory at <path>
in the specified format. Format accepts filesize in blocks (%b), filename (%n),
block size (%o), replication (%r), modification date (%y, %Y)
-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...
Changes permissions of a file.
This works similar to shell's chmod with a few exceptions.
-R modifies the files recursively. This is the only option
currently supported.
MODE Mode is same as mode used for chmod shell command.
Only letters recognized are 'rwxX'. E.g. a+r,g-w,+rwx,o=r
OCTALMODE Mode specifed in 3 digits. Unlike shell command,
this requires all three digits.
E.g. 754 is same as u=rwx,g=rx,o=r
If none of 'augo' is specified, 'a' is assumed and unlike
shell command, no umask is applied.
-chown [-R] [OWNER][:[GROUP]] PATH...
Changes owner and group of a file.
This is similar to shell's chown with a few exceptions.
-R modifies the files recursively. This is the only option
currently supported.
If only owner or group is specified then only owner or
group is modified.
The owner and group names may only cosists of digits, alphabet,
and any of '-_.@/' i.e. [-_.@/a-zA-Z0-9]. The names are case
sensitive.
WARNING: Avoid using '.' to separate user name and group though
Linux allows it. If user names have dots in them and you are
using local file system, you might see surprising results since
shell command 'chown' is used for local files.
-chgrp [-R] GROUP PATH...
This is equivalent to -chown ... :GROUP ...
-count[-q] <path>: Count the number of directories, files and bytes under the paths
that match the specified file pattern. The output columns are:
DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME or
QUOTA REMAINING_QUATA SPACE_QUOTA REMAINING_SPACE_QUOTA
DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME
-help [cmd]: Displays help for given command or all commands if none
is specified.
To list all the file(s) and directories under the root of HDFS issue
the following command:
The following will be the output:
Output-3
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2013-12-25 18:26 /home
Let us create a directory called data in the
root of HDFS. To do that issue the following command:
This command will not generate an output.
Re-issuing the ls command will generate
the following output:
Output-4
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2013-12-26 19:28 /data
drwxr-xr-x - hadoop supergroup 0 2013-12-25 18:26 /home
Let us create a sample file in the local Linux file system to be stored
in HDFS. We will create a file with a listing of all the jars under
$HADOOP_PREFIX/lib and save it in Downloads/Hadoop-Jars.txt.
To store this file in HDFS, issue the following command:
hadoop fs -put ./Downloads/Hadoop-Jars.txt /data
This command will not generate an output.
Now issue the following command to list all the file(s) under the /data
directory of HDFS:
The following will be the output:
Output-5
Found 1 items
-rw-r--r-- 2 hadoop supergroup 3934 2013-12-26 19:33 /data/Hadoop-Jars.txt
The number in the second column from the listing above for the file
/data/Hadoop-Jars.txt indicates the replication factor.
To recurively list all the file(s) under the root directory of HDFS,
issue the following command:
The following will be the output:
Output-6
drwxr-xr-x - hadoop supergroup 0 2013-12-26 19:33 /data
-rw-r--r-- 2 hadoop supergroup 3934 2013-12-26 19:33 /data/Hadoop-Jars.txt
drwxr-xr-x - hadoop supergroup 0 2013-12-25 18:26 /home
drwxr-xr-x - hadoop supergroup 0 2013-12-25 18:26 /home/hadoop
drwxr-xr-x - hadoop supergroup 0 2013-12-25 18:26 /home/hadoop/hadoop-data
drwxr-xr-x - hadoop supergroup 0 2013-12-26 12:48 /home/hadoop/hadoop-data/mapred
drwx------ - hadoop supergroup 0 2013-12-26 12:48 /home/hadoop/hadoop-data/mapred/system
-rw------- 2 hadoop supergroup 4 2013-12-26 12:48 /home/hadoop/hadoop-data/mapred/system/jobtracker.info
To display the contents of the file /data/Hadoop-Jars.txt from HDFS,
issue the following command:
hadoop fs -cat /data/Hadoop-Jars.txt
The following will be the output:
Output-7
-rw-rw-r-- 1 hadoop hadoop 43398 Jul 22 18:26 hadoop-1.2.1/lib/asm-3.2.jar
-rw-rw-r-- 1 hadoop hadoop 116219 Jul 22 18:26 hadoop-1.2.1/lib/aspectjrt-1.6.11.jar
-rw-rw-r-- 1 hadoop hadoop 8918431 Jul 22 18:26 hadoop-1.2.1/lib/aspectjtools-1.6.11.jar
-rw-rw-r-- 1 hadoop hadoop 188671 Jul 22 18:26 hadoop-1.2.1/lib/commons-beanutils-1.7.0.jar
-rw-rw-r-- 1 hadoop hadoop 206035 Jul 22 18:26 hadoop-1.2.1/lib/commons-beanutils-core-1.8.0.jar
-rw-rw-r-- 1 hadoop hadoop 41123 Jul 22 18:26 hadoop-1.2.1/lib/commons-cli-1.2.jar
-rw-rw-r-- 1 hadoop hadoop 58160 Jul 22 18:26 hadoop-1.2.1/lib/commons-codec-1.4.jar
-rw-rw-r-- 1 hadoop hadoop 575389 Jul 22 18:26 hadoop-1.2.1/lib/commons-collections-3.2.1.jar
-rw-rw-r-- 1 hadoop hadoop 298829 Jul 22 18:26 hadoop-1.2.1/lib/commons-configuration-1.6.jar
-rw-rw-r-- 1 hadoop hadoop 13619 Jul 22 18:26 hadoop-1.2.1/lib/commons-daemon-1.0.1.jar
-rw-rw-r-- 1 hadoop hadoop 143602 Jul 22 18:26 hadoop-1.2.1/lib/commons-digester-1.8.jar
-rw-rw-r-- 1 hadoop hadoop 112341 Jul 22 18:26 hadoop-1.2.1/lib/commons-el-1.0.jar
-rw-rw-r-- 1 hadoop hadoop 279781 Jul 22 18:26 hadoop-1.2.1/lib/commons-httpclient-3.0.1.jar
-rw-rw-r-- 1 hadoop hadoop 163151 Jul 22 18:26 hadoop-1.2.1/lib/commons-io-2.1.jar
-rw-rw-r-- 1 hadoop hadoop 261809 Jul 22 18:26 hadoop-1.2.1/lib/commons-lang-2.4.jar
-rw-rw-r-- 1 hadoop hadoop 60686 Jul 22 18:26 hadoop-1.2.1/lib/commons-logging-1.1.1.jar
-rw-rw-r-- 1 hadoop hadoop 26202 Jul 22 18:26 hadoop-1.2.1/lib/commons-logging-api-1.0.4.jar
-rw-rw-r-- 1 hadoop hadoop 832410 Jul 22 18:26 hadoop-1.2.1/lib/commons-math-2.1.jar
-rw-rw-r-- 1 hadoop hadoop 273370 Jul 22 18:26 hadoop-1.2.1/lib/commons-net-3.1.jar
-rw-rw-r-- 1 hadoop hadoop 3566844 Jul 22 18:26 hadoop-1.2.1/lib/core-3.1.1.jar
-rw-rw-r-- 1 hadoop hadoop 58461 Jul 22 18:26 hadoop-1.2.1/lib/hadoop-capacity-scheduler-1.2.1.jar
-rw-rw-r-- 1 hadoop hadoop 70409 Jul 22 18:26 hadoop-1.2.1/lib/hadoop-fairscheduler-1.2.1.jar
-rw-rw-r-- 1 hadoop hadoop 10443 Jul 22 18:26 hadoop-1.2.1/lib/hadoop-thriftfs-1.2.1.jar
-rw-rw-r-- 1 hadoop hadoop 706710 Jul 22 18:26 hadoop-1.2.1/lib/hsqldb-1.8.0.10.jar
-rw-rw-r-- 1 hadoop hadoop 227500 Jul 22 18:26 hadoop-1.2.1/lib/jackson-core-asl-1.8.8.jar
-rw-rw-r-- 1 hadoop hadoop 668564 Jul 22 18:26 hadoop-1.2.1/lib/jackson-mapper-asl-1.8.8.jar
-rw-rw-r-- 1 hadoop hadoop 405086 Jul 22 18:26 hadoop-1.2.1/lib/jasper-compiler-5.5.12.jar
-rw-rw-r-- 1 hadoop hadoop 76698 Jul 22 18:26 hadoop-1.2.1/lib/jasper-runtime-5.5.12.jar
-rw-rw-r-- 1 hadoop hadoop 220920 Jul 22 18:26 hadoop-1.2.1/lib/jdeb-0.8.jar
-rw-rw-r-- 1 hadoop hadoop 458233 Jul 22 18:26 hadoop-1.2.1/lib/jersey-core-1.8.jar
-rw-rw-r-- 1 hadoop hadoop 147933 Jul 22 18:26 hadoop-1.2.1/lib/jersey-json-1.8.jar
-rw-rw-r-- 1 hadoop hadoop 694352 Jul 22 18:26 hadoop-1.2.1/lib/jersey-server-1.8.jar
-rw-rw-r-- 1 hadoop hadoop 321806 Jul 22 18:26 hadoop-1.2.1/lib/jets3t-0.6.1.jar
-rw-rw-r-- 1 hadoop hadoop 539912 Jul 22 18:26 hadoop-1.2.1/lib/jetty-6.1.26.jar
-rw-rw-r-- 1 hadoop hadoop 177131 Jul 22 18:26 hadoop-1.2.1/lib/jetty-util-6.1.26.jar
-rw-rw-r-- 1 hadoop hadoop 185746 Jul 22 18:26 hadoop-1.2.1/lib/jsch-0.1.42.jar
-rw-rw-r-- 1 hadoop hadoop 198945 Jul 22 18:26 hadoop-1.2.1/lib/junit-4.5.jar
-rw-rw-r-- 1 hadoop hadoop 11428 Jul 22 18:26 hadoop-1.2.1/lib/kfs-0.2.2.jar
-rw-rw-r-- 1 hadoop hadoop 391834 Jul 22 18:26 hadoop-1.2.1/lib/log4j-1.2.15.jar
-rw-rw-r-- 1 hadoop hadoop 1419869 Jul 22 18:26 hadoop-1.2.1/lib/mockito-all-1.8.5.jar
-rw-rw-r-- 1 hadoop hadoop 65261 Jul 22 18:26 hadoop-1.2.1/lib/oro-2.0.8.jar
-rw-rw-r-- 1 hadoop hadoop 134133 Jul 22 18:26 hadoop-1.2.1/lib/servlet-api-2.5-20081211.jar
-rw-rw-r-- 1 hadoop hadoop 15345 Jul 22 18:26 hadoop-1.2.1/lib/slf4j-api-1.4.3.jar
-rw-rw-r-- 1 hadoop hadoop 8601 Jul 22 18:26 hadoop-1.2.1/lib/slf4j-log4j12-1.4.3.jar
-rw-rw-r-- 1 hadoop hadoop 15010 Jul 22 18:26 hadoop-1.2.1/lib/xmlenc-0.52.jar
To check the health of HDFS and list information on the data blocks of
the file /data/Hadoop-Jars.txt and the nodes to which they have been
replicated, issue the following command:
hadoop fsck /data/Hadoop-Jars.txt -files -blocks -locations
The following will be the output:
Output-8
FSCK started by hadoop from /127.0.0.1 for path /data/Hadoop-Jars.txt at Thu Dec 26 20:08:08 EST 2013
/data/Hadoop-Jars.txt 3934 bytes, 1 block(s): OK
0. blk_3898821203252733167_1006 len=3934 repl=2 [192.168.1.16:50010, 192.168.1.12:50010]
Status: HEALTHY
Total size: 3934 B
Total dirs: 0
Total files: 1
Total blocks (validated): 1 (avg. block size 3934 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 2
Average block replication: 2.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 2
Number of racks: 1
FSCK ended at Thu Dec 26 20:08:08 EST 2013 in 1 milliseconds
The filesystem under path '/data/Hadoop-Jars.txt' is HEALTHY
As we can see from the line repl=2
[192.168.1.16:50010, 192.168.1.12:50010], we see that the data
blocks have been replicated to the two slaves hadoop-slave-1
(192.168.1.12) and hadoop-slave-2
(192.168.1.16)
To display the amount of space used (in bytes) by the files and
directories in HDFS, issue the following command:
The following will be the output:
Output-9
Found 2 items
3934 hdfs://hadoop-master:54310/data
4 hdfs://hadoop-master:54310/home
To delete the file /data/Hadoop-Jars.txt, issue the following command:
hadoop fs -rm /data/Hadoop-Jars.txt
The following will be the output:
Output-10
Deleted hdfs://hadoop-master:54310/data/Hadoop-Jars.txt
One can get information about the NameNode
by typing in the following URL in a web browser:
http://hadoop-master:50070
The following diagram in Figure-6 shows the result:
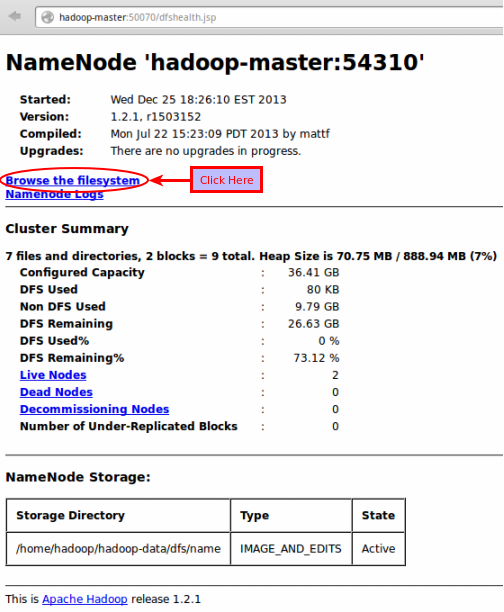
Figure-6
One can also browse HDFS by clicking on Browse the filesystem as shown in Figure-6 above.
The following is the result of clicking the link:
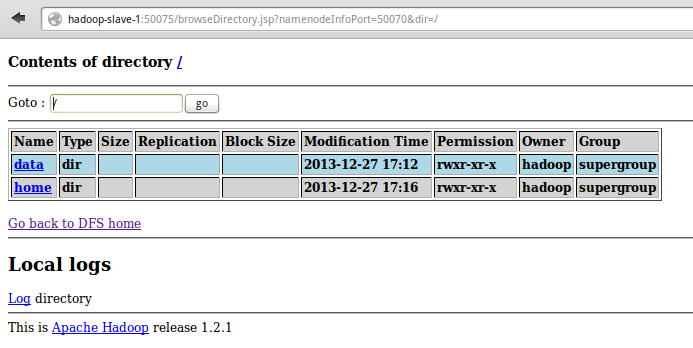
Figure-7
We have bearly scratched the surface on HDFS !!!