Figure.1
| PolarSPARC |
Exploring Kafka Streams :: Part 3
| Bhaskar S | 11/23/2021 |
Overview
In Part 2 of this series, we started to dig in a little deeper into Kafka Streams and explored the concepts around stream tasks and stream threads.
In this part of the series, we will continue to dig deeper into the other areas of Kafka Streams.
Kafka Streams Concepts
State Store and Record Cache
In Part 1, when we execute our STATEFUL application (com.polarsparc.kstreams.SurveyEventsStateful), it generated the output with the correct counts - 1 for go, 2 for Java, and 3 for Python. Ever wondered the mechanics behind this behavior ???
STATEFUL means the application has to somehow maintain state of the previously occurred data events. The storage abstraction that allows Kafka Streams stateful processors (such as count(), aggregate(), etc.) to remember state of the previously occurred data events is called a State Store.
By default, the state store in Kafka Streams is locally embedded at the stream task level. The state store can be either an in-memory key-value cache (such as a hash map) or a disk based key-value persistent store. The default state store used in Kafka Streams is RocksDB, a high-performance, disk based key-value persistent store.
As the Kafka Streams stateful processors (such as count(), aggregate(), etc.) perform their aggregate operations, they generate intermediate data events (or records), which is what ultimately gets saved in the local state store. If their is a high velocity of data events coming into these stateful processors, they can overwhelm the local state store as well as the next processor in the topology. This is where the Record Cache comes into play. It is an in-memory cache that allows for throttling (buffering) and batching of the intermediate data events to both the local state store and the next downstream processor in the pipeline.
NOTE :: The cache size is equally distributed among the number of stream threads. In other words, if M is the total size in bytes and there are N threads, then the size of the record cache in each stream thread is M/N bytes.
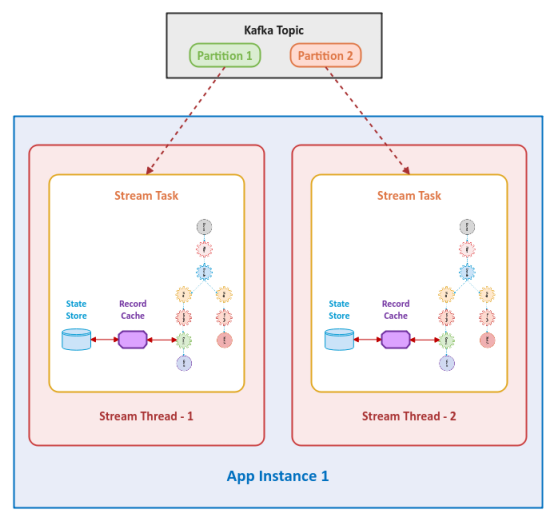
The following illustration depicts a state store associated with each stream task in a Kafka Streams application:
Hands-on with Kafka Streams
We will update the Java utility class KafkaConsumerConfig from the Common module located in the directory $HOME/java/KafkaStreams/Common to add a new convenience method as shown below:
/*
* Name: Kafka Consumer Configuration
* Author: Bhaskar S
* Date: 11/10/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import java.util.Properties;
public final class KafkaConsumerConfig {
public static Properties kafkaConfigurationOne(String appId) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, appId);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:20001");
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return config;
}
public static Properties kafkaConfigurationTwo(String appId, int numThr) {
Properties config = kafkaConfigurationOne(appId);
config.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, numThr);
return config;
}
public static Properties kafkaConfigurationThree(String appId, int numThr, long totMemSz) {
Properties config = kafkaConfigurationTwo(appId, numThr);
config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000);
config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, totMemSz);
return config;
}
private KafkaConsumerConfig() {}
}
The property StreamsConfig.COMMIT_INTERVAL_MS_CONFIG allows one to configure how often the state in the record cache is flushed to the state store and forwarded to the downstream processor. The default value is 30 seconds.
The property StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG allows one to configure the total size of the record cache(s) for the Kafka Streams application instance. Note this size will be equally divided amongst all the number of stream threads. The default value is 10 MB.
Since we modified the Common module, we need to once again compile and deploy the Common module so that the other Java modules can use it. To do that, open a terminal window and run the following commands:
$ $HOME/java/KafkaStreams/Common
$ mvn clean install
Second Application
We will re-use the Second module to demonstrate a STATEFUL Kafka Streams application to consume data events from the multi-partition Kafka topic coffee-flavors to demonstrate the concept of state store and record cache. Each event from the source will be in the form user:flavor, where 'user' is the key and 'flavor' is the value. The application will re-map the events to aggregate and count by flavors.
The following is the Java based STATEFUL Kafka Streams application that consumes and processes events from the Kafka topic coffee-flavors:
/*
* Name: Coffee Flavors (Stateful)
* Author: Bhaskar S
* Date: 11/23/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Set;
public class CoffeeFlavorsStateful {
private static final String COFFEE_FLAVORS = "coffee-flavors";
// Arguments: [1 or 2] [0 or 1024]
public static void main(String[] args) {
int numThreads = 1;
if (args.length == 1 || args.length == 2) {
if (args[0].equals("2")) {
numThreads = 2;
}
}
long totalMemSize = 0L;
if (args.length == 2) {
if (args[1].equals("1024")) {
totalMemSize = 1024L;
}
}
Logger log = LoggerFactory.getLogger(CoffeeFlavorsStateful.class.getName());
Set<String> flavorSet = Set.copyOf(Arrays.asList("caramel", "hazelnut", "mocha", "peppermint"));
log.info(String.format("---> Num of stream threads: %d", numThreads));
log.info(String.format("---> Total size of record cache: %d", totalMemSize));
StreamsConfig config;
if (totalMemSize == 0L) {
config = new StreamsConfig(KafkaConsumerConfig.kafkaConfigurationTwo(
"coffee-flavor-2", numThreads));
} else {
config = new StreamsConfig(KafkaConsumerConfig.kafkaConfigurationThree(
"coffee-flavor-2", numThreads, totalMemSize));
}
StreamsBuilder builder = new StreamsBuilder();
Serde<String> stringSerde = Serdes.String();
KStream<String, String> stream = builder.stream(COFFEE_FLAVORS, Consumed.with(stringSerde, stringSerde));
KTable<String, Long> table = stream
.peek((user, flavor) -> log.info(String.format("---> [Start] User: %s, Flavor: %s", user, flavor)))
.map((user, flavor) -> KeyValue.pair(user.toLowerCase(), flavor.toLowerCase()))
.filter((user, flavor) -> flavorSet.contains(flavor))
.map((user, flavor) -> KeyValue.pair(flavor, user))
.groupByKey()
.count();
table.toStream()
.foreach((flavor, user) -> log.info(String.format("---> [Final] %s - %s", flavor, user)));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
Before we proceed further, let us take a peek at the current state of Kafka data directory. Open a terminal window and execute the following command:
ls -l $HOME/kafka/data/
The following should be the typical output:
-rw-r--r-- 1 polarsparc polarsparc 0 Nov 23 13:55 cleaner-offset-checkpoint drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 coffee-flavors-0 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 coffee-flavors-1 -rw-r--r-- 1 polarsparc polarsparc 4 Nov 23 13:55 log-start-offset-checkpoint -rw-r--r-- 1 polarsparc polarsparc 88 Nov 23 13:55 meta.properties -rw-r--r-- 1 polarsparc polarsparc 21 Nov 23 13:55 recovery-point-offset-checkpoint -rw-r--r-- 1 polarsparc polarsparc 59 Nov 23 13:56 replication-offset-checkpoint drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 survey-event-0
Now is time to test the code from Listing.2. To do that, open a terminal window and execute the following commands:
$ $HOME/java/KafkaStreams/Second
$ mvn clean compile
$ mvn exec:java -Dexec.mainClass=com.polarsparc.kstreams.CoffeeFlavorsStateful
The following should be the typical output:
[com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> Num of stream threads: 1 [com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> Total size of record cache: 0 [com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO org.apache.kafka.streams.StreamsConfig - StreamsConfig values: application.id = coffee-flavor-2 bootstrap.servers = [localhost:20001] ... cache.max.bytes.buffering = 10485760 commit.interval.ms = 30000 ... state.dir = /tmp/kafka-streams ... SNIP ... [com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] WARN org.apache.kafka.streams.processor.internals.StateDirectory - Using an OS temp directory in the state.dir property can cause failures with writing the checkpoint file due to the fact that this directory can be cleared by the OS. Resolved state.dir: [/tmp/kafka-streams] [com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO org.apache.kafka.streams.processor.internals.StateDirectory - No process id found on disk, got fresh process id 81e2a047-91a8-41ad-bc82-3675ba1c25bc ... SNIP ... [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer clientId=coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1-consumer, groupId=coffee-flavor-2] Subscribed to topic(s): coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition, coffee-flavors ... SNIP ... [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1-consumer, groupId=coffee-flavor-2] Updating assignment with Assigned partitions: [coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1, coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0, coffee-flavors-0, coffee-flavors-1] Current owned partitions: [] Added partitions (assigned - owned): [coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1, coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0, coffee-flavors-0, coffee-flavors-1] Revoked partitions (owned - assigned): [] [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1-consumer, groupId=coffee-flavor-2] Notifying assignor about the new Assignment(partitions=[coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0, coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1, coffee-flavors-0, coffee-flavors-1], userDataSize=88) [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamsPartitionAssignor - stream-thread [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1-consumer] No followup rebalance was requested, resetting the rebalance schedule. [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.TaskManager - stream-thread [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] Handle new assignment with: New active tasks: [1_0, 0_1, 0_0, 1_1] New standby tasks: [] Existing active tasks: [] Existing standby tasks: [] [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1-consumer, groupId=coffee-flavor-2] Adding newly assigned partitions: coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1, coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0, coffee-flavors-0, coffee-flavors-1 ... SNIP ... [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [coffee-flavor-2-81e2a047-91a8-41ad-bc82-3675ba1c25bc-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING ... SNIP ...
Notice the state store, by default is stored in the directory /tmp/kafka-streams.
Also, notice the creation of additional topics partitions that are associated with the state store.
Let us take a peek at the state store directory by executing the following command:
tree /tmp/kafka-streams
The following should be the typical output:
/tmp/kafka-streams/
|-- coffee-flavor-2
|-- 1_0
| |-- rocksdb
| |-- KSTREAM-AGGREGATE-STATE-STORE-0000000005
| |-- 000009.log
| |-- CURRENT
| |-- IDENTITY
| |-- LOCK
| |-- LOG
| |-- LOG.old.1637695204586083
| |-- MANIFEST-000008
| |-- OPTIONS-000011
| |-- OPTIONS-000013
|-- 1_1
| |-- rocksdb
| |-- KSTREAM-AGGREGATE-STATE-STORE-0000000005
| |-- 000009.log
| |-- CURRENT
| |-- IDENTITY
| |-- LOCK
| |-- LOG
| |-- LOG.old.1637695204630370
| |-- MANIFEST-000008
| |-- OPTIONS-000011
| |-- OPTIONS-000013
|-- kafka-streams-process-metadata
Now, let us take a peek at the current state of Kafka data directory by executing the following command:
ls -l $HOME/kafka/data/
The following should be the typical output:
-rw-r--r-- 1 polarsparc polarsparc 0 Nov 23 13:55 cleaner-offset-checkpoint drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 14:01 coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog-0 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 14:01 coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog-1 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 14:01 coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 14:01 coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 coffee-flavors-0 drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 coffee-flavors-1 -rw-r--r-- 1 polarsparc polarsparc 4 Nov 23 14:02 log-start-offset-checkpoint -rw-r--r-- 1 polarsparc polarsparc 88 Nov 23 13:55 meta.properties -rw-r--r-- 1 polarsparc polarsparc 1538 Nov 23 14:02 recovery-point-offset-checkpoint -rw-r--r-- 1 polarsparc polarsparc 1538 Nov 23 14:02 replication-offset-checkpoint drwxr-xr-x 2 polarsparc polarsparc 4096 Nov 23 13:55 survey-event-0
Notice the creation of the following 4 new sub-directories:
coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog-0
coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog-1
coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-0
coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition-1
The Kafka topics with the suffix *-changelog-X are the replicated changelog for the state store that persists the aggregated data events from the count() operation. These topics are created to ensure the state store is able to recover in case of failures.
The Kafka topics with the suffix *-repartition-X are for re-distributing the data events based on the new key (due to the groupByKey() or map() operations that change the key) such that they end up in the appropriate stream thread for further processing.
To display the details of the state store changelog Kafka topic using docker, execute the following command:
docker run --rm --net=host confluentinc/cp-kafka:7.0.0 kafka-topics --bootstrap-server localhost:20001 --describe --topic coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog
The following should be the typical output:
Topic: coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog TopicId: b65mEQ7pTUCDh20_NX1oDA PartitionCount: 2 ReplicationFactor: 1 Configs: cleanup.policy=compact,message.timestamp.type=CreateTime
Topic: coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog Partition: 0 Leader: 1 Replicas: 1Isr: 1
Topic: coffee-flavor-2-KSTREAM-AGGREGATE-STATE-STORE-0000000005-changelog Partition: 1 Leader: 1 Replicas: 1Isr: 1
Notice that the state store changelog Kafka topic is partitioned as well, so that each stream task accessing the state store has its own dedicated changelog topic partition.
Now a question may arise - what are those LONG numbers in the topic names ???
In order to explain this we will make some changes to the code to display the Kafka Streams topology.
In addition, we will change the state store location to the directory $HOME/kafka/state since the default /tmp/kafka-streams is not a safe location as it will get wiped off when the host reboots.
We will update the Java utility class KafkaConsumerConfig from the Common module located in the directory $HOME/java/KafkaStreams/Common as shown below:
/*
* Name: Kafka Consumer Configuration
* Author: Bhaskar S
* Date: 11/10/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import java.util.Properties;
public final class KafkaConsumerConfig {
public static Properties kafkaConfigurationOne(String appId) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, appId);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:20001");
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return config;
}
public static Properties kafkaConfigurationTwo(String appId, int numThr) {
Properties config = kafkaConfigurationOne(appId);
config.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, numThr);
config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000);
config.put(StreamsConfig.STATE_DIR_CONFIG, "/home/polarsparc/kafka/state");
return config;
}
public static Properties kafkaConfigurationThree(String appId, int numThr, long totMemSz) {
Properties config = kafkaConfigurationTwo(appId, numThr);
config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, totMemSz);
return config;
}
private KafkaConsumerConfig() {}
}
The property StreamsConfig.STATE_DIR_CONFIG allows one to configure the location of the state store.
Since we modified the Common module, we need to once again compile and deploy the Common module so that the other Java modules can use it. To do that, open a terminal window and run the following commands:
$ $HOME/java/KafkaStreams/Common
$ mvn clean install
The following is the modified Java based STATEFUL Kafka Streams application that consumes and processes events from the Kafka topic coffee-flavors:
/*
* Name: Coffee Flavors (Stateful)
* Author: Bhaskar S
* Date: 11/23/2021
* Blog: https://www.polarsparc.com
*/
package com.polarsparc.kstreams;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Set;
public class CoffeeFlavorsStateful {
private static final String COFFEE_FLAVORS = "coffee-flavors";
// Arguments: [1 or 2] [0 or 1024]
public static void main(String[] args) {
int numThreads = 1;
if (args.length == 1 || args.length == 2) {
if (args[0].equals("2")) {
numThreads = 2;
}
}
long totalMemSize = 0L;
if (args.length == 2) {
if (args[1].equals("1024")) {
totalMemSize = 1024L;
}
}
Logger log = LoggerFactory.getLogger(CoffeeFlavorsStateful.class.getName());
Set<String> flavorSet = Set.copyOf(Arrays.asList("caramel", "hazelnut", "mocha", "peppermint"));
log.info(String.format("---> Num of stream threads: %d", numThreads));
log.info(String.format("---> Total size of record cache: %d", totalMemSize));
StreamsConfig config;
if (totalMemSize == 0L) {
config = new StreamsConfig(KafkaConsumerConfig.kafkaConfigurationTwo(
"coffee-flavor-2", numThreads));
} else {
config = new StreamsConfig(KafkaConsumerConfig.kafkaConfigurationThree(
"coffee-flavor-2", numThreads, totalMemSize));
}
StreamsBuilder builder = new StreamsBuilder();
Serde<String> stringSerde = Serdes.String();
KStream<String, String> stream = builder.stream(COFFEE_FLAVORS, Consumed.with(stringSerde, stringSerde));
KTable<String, Long> table = stream
.peek((user, flavor) -> log.info(String.format("---> [Start] User: %s, Flavor: %s", user, flavor)))
.map((user, flavor) -> KeyValue.pair(user.toLowerCase(), flavor.toLowerCase()))
.filter((user, flavor) -> flavorSet.contains(flavor))
.map((user, flavor) -> KeyValue.pair(flavor, user))
.groupByKey()
.count();
table.toStream()
.foreach((flavor, user) -> log.info(String.format("---> [Final] %s - %s", flavor, user)));
Topology topology = builder.build();
log.info(String.format("---> %s", topology.describe().toString()));
KafkaStreams streams = new KafkaStreams(topology, config);
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
The code from Listing.4 above needs some explanation:
The method build() on the class StreamsBuilder returns an instance of the class org.apache.kafka.streams.Topology.
The method describe() on the class Topology allows one to display the Kafka Streams data pipeline topology.
Now to test the code from Listing.4, open a terminal window and execute the following commands:
$ $HOME/java/KafkaStreams/Second
$ mvn clean compile
$ mvn exec:java -Dexec.mainClass=com.polarsparc.kstreams.CoffeeFlavorsStateful
The following should be the typical output:
[com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> Num of stream threads: 1
[com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> Total size of record cache: 0
[com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO org.apache.kafka.streams.StreamsConfig - StreamsConfig values:
... SNIP ...
state.dir = /home/polarsparc/kafka/state
... SNIP ...
[com.polarsparc.kstreams.CoffeeFlavorsStateful.main()] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [coffee-flavors])
--> KSTREAM-PEEK-0000000001
Processor: KSTREAM-PEEK-0000000001 (stores: [])
--> KSTREAM-MAP-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-MAP-0000000002 (stores: [])
--> KSTREAM-FILTER-0000000003
<-- KSTREAM-PEEK-0000000001
Processor: KSTREAM-FILTER-0000000003 (stores: [])
--> KSTREAM-MAP-0000000004
<-- KSTREAM-MAP-0000000002
Processor: KSTREAM-MAP-0000000004 (stores: [])
--> KSTREAM-FILTER-0000000008
<-- KSTREAM-FILTER-0000000003
Processor: KSTREAM-FILTER-0000000008 (stores: [])
--> KSTREAM-SINK-0000000007
<-- KSTREAM-MAP-0000000004
Sink: KSTREAM-SINK-0000000007 (topic: KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition)
<-- KSTREAM-FILTER-0000000008
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000009 (topics: [KSTREAM-AGGREGATE-STATE-STORE-0000000005-repartition])
--> KSTREAM-AGGREGATE-0000000006
Processor: KSTREAM-AGGREGATE-0000000006 (stores: [KSTREAM-AGGREGATE-STATE-STORE-0000000005])
--> KTABLE-TOSTREAM-0000000010
<-- KSTREAM-SOURCE-0000000009
Processor: KTABLE-TOSTREAM-0000000010 (stores: [])
--> KSTREAM-FOREACH-0000000011
<-- KSTREAM-AGGREGATE-0000000006
Processor: KSTREAM-FOREACH-0000000011 (stores: [])
--> none
<-- KTABLE-TOSTREAM-0000000010
... SNIP ...
Notice that the Kafka Streams topology starts to assign a label (with a number suffix) for each node in the graph starting with the number '0000000000' for the source of the data events. The next processor operation in the topology graph gets the next number (incremented by 1). Hence, the 'peek()' operation gets the number '0000000001' and so on. Notice the state store gets the number '0000000005'. This is what we saw earlier.
We need to publish some events to the Kafka topic coffee-flavors. Open a terminal window and run the Kafka console publisher using the following command:
$ docker run -it --rm --net=host confluentinc/cp-kafka:7.0.0 kafka-console-producer --bootstrap-server localhost:20001 --property key.separator=, --property parse.key=true --request-required-acks 1 --topic coffee-flavors
The prompt will change to >.
Enter the following events:
>Alice,Caramel
>Bob,Mocha
>Charlie,Hazelnut
>Eva,Peppermint
>Frank,Mocha
>George,Caramel
>Harry,Mocha
The following would be the additional output in the terminal running the application from Listing.4 above:
[coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Alice, Flavor: Caramel [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] caramel - 1 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Bob, Flavor: Mocha [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] mocha - 1 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Charlie, Flavor: Hazelnut [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] hazelnut - 1 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Eva, Flavor: Peppermint [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] peppermint - 1 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Frank, Flavor: Mocha [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] mocha - 2 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: George, Flavor: Caramel [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] caramel - 2 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] Processed 12 total records, ran 0 punctuators, and committed 12 total tasks since the last update [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Start] User: Harry, Flavor: Mocha [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO com.polarsparc.kstreams.CoffeeFlavorsStateful - ---> [Final] mocha - 3 [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] INFO org.apache.kafka.streams.processor.internals.StreamThread - stream-thread [coffee-flavor-2-9e49b761-fd79-424c-9f7f-c28f3309dd69-StreamThread-1] Processed 2 total records, ran 0 punctuators, and committed 2 total tasks since the last update
References