Figure.1
| PolarSPARC |
Deep Learning - Sequence-to-Sequence Model
| Bhaskar S | 11/07/2023 |
Introduction
Ever wondered how the language translation services like Google Translate worked ??? The translator service takes in an input sentence (sequence of arbitrary length words) for a given language and translates it to an output sentence (sequence of different arbitrary length words) in another language. This is where the Sequence-to-Sequence (or Seq2Seq for short) neural network model comes into play.
The concept of Seq2Seq model first appeared in a paper published by Google in 2014. Under the hood the model leverages two sets of GRU network blocks, which are referred to as the Encoder and the Decoder blocks, and are arranged such that the Encoder block feeds into the Decoder block.
In other words, the Encoder block takes in as input an arbitrary length sequence of fixed size vectors, compresses and converts them into a fixed size Context vector, which is then fed into the Decoder block for translation to an arbitrary length sequence (different from the input sequence length) of fixed size output vectors.
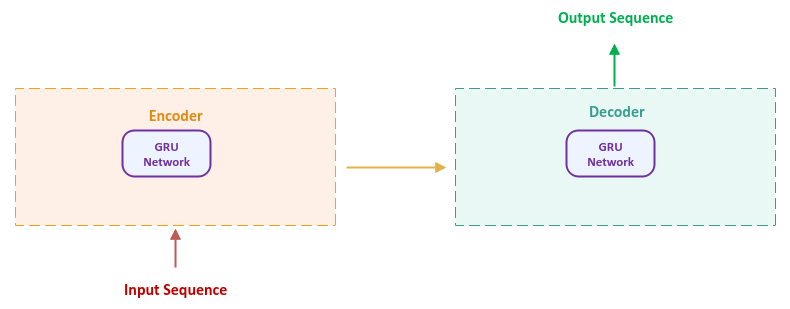
The following illustration shows the high-level abstraction of a Seq2Seq model:
Sequence-to-Sequence (Seq2Seq) Model
The Seq2Seq model is also often referred as the Encoder-Decoder model. In other words, they are used interchangeably to refer to the same thing.
Let us now dig into to details of the Encoder-Decoder model.
In the following sections, when we refer to word tokens, we are actually referring to their equivalent Vector Embedding. Also, we will introduce two special tokens - <SOS> to represent the start of sentence and <EOS> to represent the end of sentence.
Encoder
The Encoder is a GRU network that processes a sequence of tokens from the input sentence till it encounters the end of sentence token. We know from the GRU model that the final hidden state encodes and represents all of the input sequence. This final hidden state is often referred to as the Context Vector. In other words, the context vector encapsulates and preserves importtant information from the input sentence into a single vector embedding.
Decoder
The Decoder is also a GRU network that processes the context vector along with the start of sentence token, to generate a sequence of output tokens, which taken together, will form the output sentence.
The following illustration depicts the more detailed Seq2Seq language translation model:
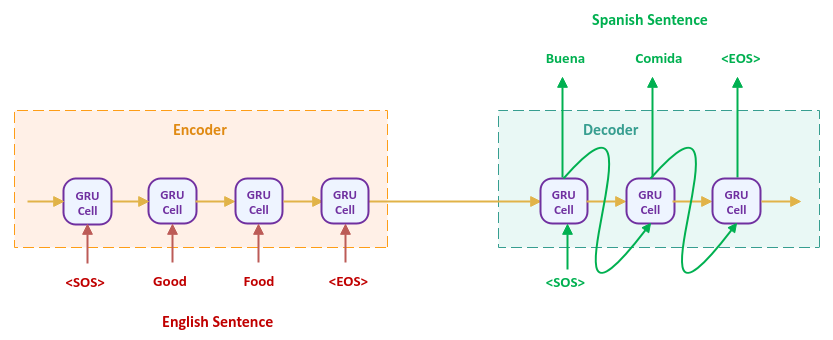
Hope this helps understand how the Encoder-Decoder model works at a high level.
Hands-on Seq2Seq Using PyTorch
To perform the translation of a sentence from English to a sentence in Spanish , we will implement the Encoder and the Decoder blocks using the GRU model.
To train the Encoder-Decoder, we will leverage the English-to-Spanish data set from the Tatoeba Project. There are other language data sets available as well, but we pick English-to-Spanish for the demo.
To import the necessary Python module(s), execute the following code snippet:
import numpy as np import re import torch from torch import nn from torch.utils.data import DataLoader, TensorDataset from unidecode import unidecode
Assuming the logged in user is alice with the home directory /home/alice, download and unzip the English-Spanish sentence translation data set into the directory /home/alice/data. This will extract a file called /home/alice/data/spa.txt.
We need a method to clean each of the sentences in both the source and target languages. Cleaning involves the following tasks:
Converting the text to lowercase
Converting the text to ASCII from Unicode
Removing some extraneous punctuation characters
To define a method to clean a sentence, execute the following code snippet:
def clean_sentence(sent):
clean = unidecode(sent.lower())
clean = re.sub('[".,!?]', '', clean)
return clean
For our demonstration, we will only deal with sentences (from either source or target) that have $5$ or less words in them for faster model training reason. To define a method to filter sentences with $5$ words or less, execute the following code snippet:
MAX_TOKENS = 5
def check_max_tokens(sent):
tokens = sent.split(' ')
if len(tokens) <= MAX_TOKENS:
return True
return False
We will need an object to store all the details about a given language (source or target). The following are some of the details about a language:
All the words in the language (the vocabulary)
Each of the sentences as a list of word tokens
Each of the sentences as a vector representation
Next, we will enforce that all the sentences have a fixed number of $8$ tokens so it can be represented as an $8$ element vector. For this we will add $3$ special tokens to the vocabulary - the start of the sentence represented as <SOS>, the end of the sentence represented as <EOS>, and a token <PAD> representing a padding word for a sentence has fewer words.
To define a class to encapsulate the details of a language, execute the following code snippet:
PAD = '' SOS = ' ' EOS = ' ' PAD_IDX = 0 SOS_IDX = 1 EOS_IDX = 2 class LanguageData: def __init__(self): self.num_words = 2 self.sentences_as_tokens = [] self.sentences_as_vectors = [] self.index2words = {PAD_IDX: PAD, SOS_IDX: SOS, EOS_IDX: EOS} self.word2index = {PAD: PAD_IDX, SOS: SOS_IDX, EOS: EOS_IDX} def add_sentence(self, sent): tokens = sent.split(' ') sent_tokens = [SOS] + tokens + [EOS] sent_tokens = sent_tokens + (MAX_VECTORS - len(sent_tokens)) * [PAD] self.sentences_as_tokens.append(sent_tokens) for tok in tokens: if not tok in self.word2index: self.word2index[tok] = self.num_words self.index2words[self.num_words] = tok self.num_words += 1 sent_vectors = [] for tok in sent_tokens: sent_vectors.append(self.word2index[tok]) self.sentences_as_vectors.append(sent_vectors) def get_sentence_vector(self, sent): tokens = sent.split(' ') sent_tokens = [SOS] + tokens + [EOS] sent_tokens = sent_tokens + (MAX_VECTORS - len(sent_tokens)) * [PAD] sent_vector = [] for tok in sent_tokens: sent_vector.append(self.word2index[tok]) return sent_vector def get_sentences_count(self): return len(self.sentences_as_tokens) def get_words_count(self): return len(self.word2index) def get_sentences(self): return self.sentences_as_tokens def get_vectors(self): return self.sentences_as_vectors def get_words(self, index_1, index_2): lst = list(self.word2index.items()) return lst[index_1:index_2] def get_word_index(self, word): return self.word2index[word] def get_index_word(self, idx): return self.index2words[idx]
Notice that we are assigning a unique number for each of the words in a language vocabulary and using those assigned numbers to create a vector representation versus using any pre-trained vector embedding for simplicity.
The english to spanish data set file /home/alice/data/spa.txt is a tab-separated file with lines with the following format:
English sentence
tab
Equivalent Spanish sentence
tab
Other details
To process the data set into the two language objects after cleaning each of the sentences and ensuring the sentence are $5$ words or less, execute the following code snippet:
eng_language_data = LanguageData()
spa_language_data = LanguageData()
with open ('./data/spa.txt', encoding='utf8') as f_en_es:
for line in f_en_es:
eng, spa, _ = line.split('\t')
eng = clean_sentence(eng)
spa = clean_sentence(spa)
# Only if the number of tokens in both english and spanish are within bounds
if check_max_tokens(eng) and check_max_tokens(spa):
eng_language_data.add_sentence(eng)
spa_language_data.add_sentence(spa)
To check the number of sentences we have captured from the data set, execute the following code snippet:
eng_language_data.get_sentences_count()
The following would be the typical output:
53957
To check the vocabulary size of the english language, execute the following code snippet:
eng_language_data.get_words_count()
The following would be a typical output:
8101
To check the vocabulary size of the spanish language, execute the following code snippet:
spa_language_data.get_words_count()
The following would be a typical output:
14752
To train the seq2seq (or encoder-decoder) language translation model, we will do it in batches.
To create the batching tensor objects, execute the following code snippet:
batch_sz = 64 X = np.array(eng_language_data.get_vectors()) y = np.array(spa_language_data.get_vectors()) dataset = TensorDataset(torch.from_numpy(X), torch.from_numpy(y)) loader = DataLoader(dataset, shuffle=True, batch_size=batch_sz)
To initialize variables for the embedding size, the input vocabulary size, the output vocabulary size, the hidden size, and the dropout rate, execute the following code snippet:
embed_size = 128 input_size = eng_language_data.get_words_count() output_size = spa_language_data.get_words_count() hidden_size = 128 dropout_rate = 0.2
To create a GRU based Encoder model, execute the following code snippet:
class SeqEncoderGRU(nn.Module):
def __init__(self, input_sz, embed_sz, hidden_sz):
super(SeqEncoderGRU, self).__init__()
# Embedding layer that encodes input of input_sz to a vector of size embed_sz
self.embedding = nn.Embedding(input_sz, embed_sz)
# GRU cell that takes an input of size embed_sz and generates an output hidden state of size hidden_sz
# The parameter batch_first=True is IMPORTANT as the input will be in the form [batch, sequence, features]
self.gru = nn.GRU(embed_sz, hidden_size=hidden_sz, batch_first=True)
# Regularization using a dropout layer
self.dropout = nn.Dropout(dropout_rate)
def forward(self, inp):
# Encode input into vector representation
embedded = self.dropout(self.embedding(inp))
# Feed vector representation of the input to the GRU model at each time step
output, hidden = self.gru(embedded)
# Generate the output and the hidden state
return output, hidden
To create an instance of the SeqEncoderGRU model, execute the following code snippet:
seq_encoder = SeqEncoderGRU(input_size, embed_size, hidden_size)
To create a GRU based Decoder model, execute the following code snippet:
class SeqDecoderGRU(nn.Module):
def __init__(self, output_sz, embed_sz, hidden_sz):
super(SeqDecoderGRU, self).__init__()
# Encode the target into vector representation
self.embedding = nn.Embedding(output_sz, embed_sz)
# Apply ReLU activation
self.relu = nn.ReLU()
# GRU cell that takes an input of size embed_sz and generates an output hidden state of size hidden_sz
# The parameter batch_first=True is IMPORTANT as the input will be in the form [batch, sequence, features]
self.gru = nn.GRU(embed_sz, hidden_size=hidden_sz, batch_first=True)
# Translate the hidden state of size hidden_sz to an output of size output_sz
self.linear = nn.Linear(hidden_sz, output_sz)
# Apply softmax function
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, enc_outputs, enc_hidden, target=None):
# Extract the batch size from the encoder input
batch_sz = enc_outputs.size(0)
# The first input to the decoder is the SOS
dec_input = torch.empty(batch_sz, 1, dtype=torch.long).fill_(eng_language_data.get_word_index(SOS))
# The initial hidden state comes from the encoder
dec_hidden = enc_hidden
# For each input word, generate the corresponding translated word. If the translated word is specified
# during training via the target, use that feed to the next time step during the training phase
dec_outputs = []
for i in range(MAX_VECTORS):
dec_output, dec_hidden = self.forward_next_step(dec_input, dec_hidden)
dec_outputs.append(dec_output)
if target is not None:
# Use the specified target to the next time step during training
dec_input = target[:, i].unsqueeze(1)
else:
# Use the predicted target to the next time step during testing
_, next_input = dec_output.topk(1)
dec_input = next_input.squeeze(-1).detach()
dec_outputs = torch.cat(dec_outputs, dim=1)
# Determine the probabilities of the target prediction at the last time step
dec_outputs = self.softmax(dec_outputs)
return dec_outputs, dec_hidden
def forward_next_step(self, inp, hid):
output = self.embedding(inp)
output = self.relu(output)
output, hidden = self.gru(output, hid)
output = self.linear(output)
return output, hidden
To create an instance of the SeqDecoderGRU model, execute the following code snippet:
seq_decoder = SeqDecoderGRU(input_size, embed_size, hidden_size)
Given that we are training in batches, each epoch will involve training the encoder-decoder model for all the batches from the data set. For better management, we will encapsulate each training epoch in a method.
To define the method which represents a training epoch to iteratively train the model in batches, make a prediction, compute the loss, and execute the backward pass to adjust the parameters, execute the following code snippet:
learning_rate = 0.01
criterion = nn.NLLLoss()
encoder_optimizer = torch.optim.Adam(seq_encoder.parameters(), lr=learning_rate)
decoder_optimizer = torch.optim.Adam(seq_decoder.parameters(), lr=learning_rate)
def train_per_epoch(loader, encoder, decoder, loss_func, enc_optimizer, dec_optimizer):
total_loss = 0
for src_input, trg_output in loader:
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
# Feed each batch of source input into the encoder
enc_outputs, enc_hidden = encoder(src_input)
# Feed the results from the encoder into the decoder along with the correct target translation
dec_outputs, _ = decoder(enc_outputs, enc_hidden, trg_output)
# Compute the loss for the batch
batch_loss = loss_func(dec_outputs.view(-1, dec_outputs.size(-1)), trg_output.view(-1))
batch_loss.backward()
enc_optimizer.step()
dec_optimizer.step()
# Compute the total loss
total_loss += batch_loss.item()
return total_loss / len(loader)
To train the encoder-decoder model for a specified number of epochs, execute the following code snippet:
num_epochs = 25
for epoch in range(1, num_epochs):
loss = train_per_epoch(train_loader, seq_encoder, seq_decoder, criterion, encoder_optimizer, decoder_optimizer)
print(f'epoch: {epoch}, loss: {loss}')
The following would be a typical output:
epoch: 1, loss: 3.0767266788000556 epoch: 2, loss: 2.2040758692257776 epoch: 3, loss: 1.7079872832667395 epoch: 4, loss: 1.387724242504174 epoch: 5, loss: 1.1864146930158233 epoch: 6, loss: 1.053284999601084 epoch: 7, loss: 0.9552433028416988 epoch: 8, loss: 0.8870768152518672 epoch: 9, loss: 0.8378837230081242 epoch: 10, loss: 0.7915594093795825 epoch: 11, loss: 0.7544960462463223 epoch: 12, loss: 0.7266215137772463 epoch: 13, loss: 0.699669285125642 epoch: 14, loss: 0.6782677689152307 epoch: 15, loss: 0.6591712704861146 epoch: 16, loss: 0.644291310466673 epoch: 17, loss: 0.6370059665157143 epoch: 18, loss: 0.6245198830797397 epoch: 19, loss: 0.6105015719953871 epoch: 20, loss: 0.6045082838143594 epoch: 21, loss: 0.5943810512763441 epoch: 22, loss: 0.5872648361640708 epoch: 23, loss: 0.5807364542054904 epoch: 24, loss: 0.5703259132578852
The training of the model will take atleast 15 minutes - so be patient !!!
Now that we have trained the encoder-decoder language translation model model, it is time to put it to test.
Given an english sentence, it first needs to be converted to a vector representation before being fed to the encoder. The output from the encoder is then fed to the decoder for the spanish translation. For convenience, we will encapsulate all this logic in a method.
To define a method for the language translation, execute the following code snippet:
def evaluate_seq2seq(eng_input):
eng_vector = np.array([eng_language_data.get_sentence_vector(eng_input)])
eng_vector = torch.from_numpy(eng_vector)
with torch.no_grad():
enc_outputs, enc_hidden = seq_encoder(eng_vector)
dec_outputs, dec_hidden = seq_decoder(enc_outputs, enc_hidden)
_, spa_output = dec_outputs.topk(1)
spa_idx_s = spa_output.squeeze()
spa_words = []
for idx in spa_idx_s:
if idx.item() == EOS_IDX:
spa_words.append(EOS)
break
spa_words.append(spa_language_data.get_index_word(idx.item()))
print(f'Spanish Translation: {" ".join(spa_words)}')
To translate a given english sentence to spanish using the trained encoder-decoder model, execute the following code snippet:
evaluate_seq2seq('good food')
The following would be a typical output:
Spanish Translation: <SOS> buena comida <EOS>
Not bad at all - the model did the correct translation in this case.
Let us try one more english sentence by executing the following code snippet:
evaluate_seq2seq('we did it')
The following would be a typical output:
Spanish Translation: <SOS> lo hicimos <EOS>
BINGO - the model once again made the correct translation !!!
References
Tab-delimited Bilingual Sentence Pairs
Sequence to Sequence Learning with Neural Networks