Milvus Architecture
| PolarSPARC |
Hands-On with Milvus Vector Database
| Bhaskar S | 10/13/2023 |
Overview
The world we live in today, generates a variety of UNSTRUCTURED data objects, such as, Audio clips, Images, Social media posts, Video clips, etc. These data objects have no defined standard features and hence are hard to store and retrieve in a consistent manner, for future data analysis.
For example, how does one compare a set of images and say that images one and five are that of a Tiger ??? Or, how does one say a set of social media posts are related to Covid ???
One of the commonly used patterns to handle these unstructured data objects is to persist them, along with the appropriate metadata key-value tags, in the big data stores, like Hadoop or S3, and process them using frameworks like Apache Spark. This approach is not reliable or scalable as it involves manually tagging by humans.
With the rapid progress being made in the Deep Learning space, there is a need for a different approach to the storage and retrieval of the unstructured data objects.
This is where the exciting world of Vector Database(s) come into play.
In the article Deep Learning - Word Embeddings with Word2Vec, we explained and demonstrated the approach to representing words as Vectors in an n-dimensional space. Similar techniques exists, which can be applied to other unstructured data objects, such as, Audio, Images, Video, etc.
In other words, a Vector Database persists unstructured data objects as their equivalent vector embeddings and indexes them for efficient and fast similarity searches (Document Similarity), in addition to supporting the traditional queries.
Milvus is an open source, highly performant and scalable Vector Database that is specifically designed to handle queries on vector embeddings.
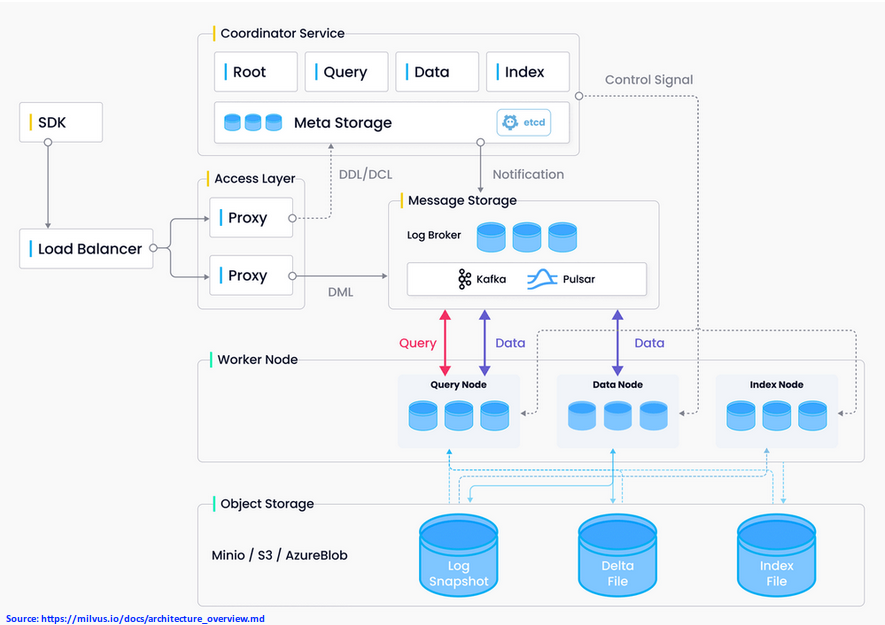
Milvus Architecture
For our hands-on demonstration, we will setup Milvus in a standalone mode, which is ideal for development and testing purposes.
Milvus leverages etcd as the metadata storage for storing the service registrations, heartbeat checks, information about the various components, and the checkpoints of the core components that would useful during recovery.
In addition, Milvus uses minio as the storage engine for persisting and retrieving the data log snapshoty files, index files, and intermediate query results.
The following illustration depicts the high level technical architecture of Milvus platform:
Now for some basic terminology definitions in Milvus.
A Collection is similar to a table in the traditional Relational Database. A Database is a set of one or more Collections. An Index on a Collection enables for faster queries/searches of data in that Collection.
The requests to create and manipulate of these database objects (Database, Collection, Index, etc) are called Data Definition Language (or DDL for short). On the other hand, the requests to create and/or mutate data in a Collection is referred to as Data Manipulation Language (or DML for short).
Now for some basic high-level explanation of the core layers in Milvus.
The Worker Node layer is the workhorse of the system and is designed to be stateless for scalability reasons. It is responsible for handling all the DML operations. It consists of the following three types of Nodes:
Data Node - Handles the inserts, updates, and delete of the DML requests, packs them into log snapshots, which are then stored in the object storage (minio )
Index Node - Responsible for building the index files as data is inserted into the system
Query Node - Responsible for loading data and index files from the object storage and performing the queries/searches for data
The Coordinator Service layer is resonsible for routing all the DDL and DML operations. It consists of the following four types of Coordinators:
Root Coordinator - Handles all the DDL requests and is the time keeper (referred to as the Time Oracle) of the system
Data Coordinator - Manages the metadata for DML requests and is responsible for the various background data operations, such as, flushing data to storage, compacting data, etc
Index Coordinator - Responsible for assigning index building tasks to the Index Node(s) and for maintaining the index matadata on which index file points to which Collection data file(s)
Query Coordinator - Responsible for assigning query/search tasks to the Query Node(s)
The Log Broker layer acts as the pub-sub system for all the DML requests. The Worker Node(s) act as the subscribers to handle the DML requests. For the standalone Milvus system, RocksDB acts as the Log Broker. It also supports Kafka or Pulsar for the pub-sub system.
The Access Layer contains the Proxy which acts as the user endpoint for performing all the operations in the platform. The Proxy performs some pre-checks, such as, making sure the requested objects exists and they conform to the schema definition. Once the checks pass, it routes all the DDL requests to the Coordinator and all the DML requests to the Log Broker.
Installation and Setup
The installation is on a Ubuntu 22.04 LTS based Linux desktop.
First, ensure that Python 3.x programming language is installed in Linux desktop.
Next, ensure that Docker is installed and setup. Else, refer to the article Introduction to Docker for help.
Finally, ensure that Docker Compose is installed and setup. Else, refer to the article Introduction to Docker Compose for help.
Assuming that we are logged in as alice and the current working directory is the home directory /home/alice, we will setup a directory structure by executing the following commands in a terminal window:
$ mkdir -p $HOME/milvus/etcd
$ mkdir -p $HOME/milvus/minio
$ mkdir -p $HOME/milvus/milvus
$ mkdir -p $HOME/milvus/glove
Now, change the current working directory to the directory /home/alice/milvus. In the following paragraphs we will refer to this location as $MILVUS_HOME.
For our exploration, we will be downloading and using the following three docker images:
Etcd - quay.io/coreos/etcd:v3.5.9
MinIO - minio/minio:RELEASE.2023-09-30T07-02-29Z
Milvus - milvusdb/milvus:v2.3.1
To pull and download the docker image for Etcd, execute the following command:
$ docker pull quay.io/coreos/etcd:v3.5.9
The following should be the typical output:
v3.5.9: Pulling from coreos/etcd dd5ad9c9c29f: Pull complete 960043b8858c: Pull complete b4ca4c215f48: Pull complete eebb06941f3e: Pull complete 02cd68c0cbf6: Pull complete d3c894b5b2b0: Pull complete b40161cd83fc: Pull complete 46ba3f23f1d3: Pull complete 4fa131a1b726: Pull complete 654ed51d2180: Pull complete 5f673cfffa4e: Pull complete daea03978d14: Pull complete 1191a2487b77: Pull complete eec65f887b31: Pull complete Digest: sha256:18ca110b5ce9a177bb80d6b4a08d73bda54b549d7a0eb6f66e6da69bf919c63f Status: Downloaded newer image for quay.io/coreos/etcd:v3.5.9
Next, to pull and download the docker image for MinIO, execute the following command:
$ docker pull minio/minio:RELEASE.2023-09-30T07-02-29Z
The following should be the typical output:
RELEASE.2023-09-30T07-02-29Z: Pulling from minio/minio 0cbafc6a7793: Pull complete 0c06e955dc3b: Pull complete 5bf3b024e1b0: Pull complete c3041f06b66f: Pull complete 1ef03837ebc0: Pull complete 9d74ffa4e082: Pull complete Digest: sha256:6262bc9a2730eeaf16be1bf436a3c2bca2ab76639f113778601a9f89c1485b56 Status: Downloaded newer image for minio/minio:RELEASE.2023-09-30T07-02-29Z docker.io/minio/minio:RELEASE.2023-09-30T07-02-29Z
Finally, to pull and download the docker image for Milvus, execute the following command:
$ docker pull milvusdb/milvus:v2.3.1
The following should be the typical output:
v2.3.1: Pulling from milvusdb/milvus d5fd17ec1767: Pull complete 165ae08a30c6: Pull complete cad7a9c60b89: Pull complete d4570c56711f: Pull complete a87594eaaa1d: Pull complete 1f27396f6efc: Pull complete fe556ec02776: Pull complete Digest: sha256:9f37c7100c44be8e7419c55f285c2963ee4d25c71951a2325614a4565a03d7e6 Status: Downloaded newer image for milvusdb/milvus:v2.3.1 docker.io/milvusdb/milvus:v2.3.1
We are going to leverage the pre-trained GloVe word embeddings provided by Stanford in our demonstration.
To download the pre-trained GloVe word embeddings to the /tmp directory, execute the following command:
$ wget -P /tmp https://nlp.stanford.edu/data/glove.6B.zip
The following should be the typical output:
--2023-10-06 20:35:29-- https://nlp.stanford.edu/data/glove.6B.zip Resolving nlp.stanford.edu (nlp.stanford.edu)... 171.64.67.140 Connecting to nlp.stanford.edu (nlp.stanford.edu)|171.64.67.140|:443... connected. HTTP request sent, awaiting response... 301 Moved Permanently Location: https://downloads.cs.stanford.edu/nlp/data/glove.6B.zip [following] --2023-10-06 19:35:29-- https://downloads.cs.stanford.edu/nlp/data/glove.6B.zip Resolving downloads.cs.stanford.edu (downloads.cs.stanford.edu)... 171.64.64.22 Connecting to downloads.cs.stanford.edu (downloads.cs.stanford.edu)|171.64.64.22|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 862182613 (822M) [application/zip] Saving to: '/tmp/glove.6B.zip' glove.6B.zip 100%[==========================================================>] 822.24M 5.02MB/s in 2m 39s 2023-10-06 20:38:09 (5.17 MB/s) - '/tmp/glove.6B.zip' saved [862182613/862182613]
We want to use the pre-trained GloVe word embeddings with 200 dimensions. To extract the desired word embeddings, execute the following command:
$ cd /tmp && unzip glove.6B.zip && mv ./glove.6B/glove.6B.200d.txt $MILVUS_HOME/glove && rm -rf glove.6B* && cd $MILVUS_HOME
The following should be the typical output:
Archive: glove.6B.zip inflating: glove.6B.50d.txt inflating: glove.6B.100d.txt inflating: glove.6B.200d.txt inflating: glove.6B.300d.txt
Finally, we need to install the Python SDK pymilvus for interacting with Milvus. To install the SDK package, execute the following command:
$ sudo pip3 pymilvus
This completes all the system installation and setup for the Milvus hands-on demonstration.
The following is the Docker Compose file located in the directory $MILVUS_HOME , which will be used to either start or stop the core Milvus services:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.9
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
user: "1000:1000"
volumes:
- ${MILVUS_HOME}/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
deploy:
resources:
limits:
memory: 4G
reservations:
memory: 2G
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-09-30T07-02-29Z
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
user: "1000:1000"
volumes:
- ${MILVUS_HOME}/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
deploy:
resources:
limits:
memory: 4G
reservations:
memory: 2G
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.3.1
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
user: "1000:1000"
volumes:
- ${MILVUS_HOME}/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
networks:
default:
name: milvus
Hands-on with Milvus
For the demonstration, we will use Milvus in a Standalone Node mode (versus deploying in a multi-node cluster mode).
To start the Milvus server, execute the following command in the terminal window:
$ docker compose -f ./milvus-docker-compose.yml up
The following would be the typical output:
[+] Running 4/4
- Network milvus Created 0.1s
- Container milvus-etcd Created 0.1s
- Container milvus-minio Created 0.1s
- Container milvus-standalone Created 0.0s
Attaching to milvus-etcd, milvus-minio, milvus-standalone
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.668024Z","caller":"flags/flag.go:113","msg":"recognized and used environment variable","variable-name":"ETCD_AUTO_COMPACTION_MODE","variable-value":"revision"}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.668353Z","caller":"flags/flag.go:113","msg":"recognized and used environment variable","variable-name":"ETCD_AUTO_COMPACTION_RETENTION","variable-value":"1000"}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.668402Z","caller":"flags/flag.go:113","msg":"recognized and used environment variable","variable-name":"ETCD_QUOTA_BACKEND_BYTES","variable-value":"4294967296"}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.668412Z","caller":"flags/flag.go:113","msg":"recognized and used environment variable","variable-name":"ETCD_SNAPSHOT_COUNT","variable-value":"50000"}
milvus-etcd | {"level":"warn","ts":"2023-10-07T16:45:32.669197Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.669472Z","caller":"etcdmain/etcd.go:73","msg":"Running: ","args":["etcd","-advertise-client-urls=http://127.0.0.1:2379","-listen-client-urls","http://0.0.0.0:2379","--data-dir","/etcd"]}
milvus-etcd | {"level":"warn","ts":"2023-10-07T16:45:32.669524Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.669531Z","caller":"embed/etcd.go:127","msg":"configuring peer listeners","listen-peer-urls":["http://localhost:2380"]}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.670701Z","caller":"embed/etcd.go:135","msg":"configuring client listeners","listen-client-urls":["http://0.0.0.0:2379"]}
milvus-etcd | {"level":"info","ts":"2023-10-07T16:45:32.670783Z","caller":"embed/etcd.go:309","msg":"starting an etcd server","etcd-version":"3.5.9","git-sha":"bdbbde998","go-version":"go1.19.9","go-os":"linux","go-arch":"amd64","max-cpu-set":16,"max-cpu-available":16,"member-initialized":false,"name":"default","data-dir":"/etcd","wal-dir":"","wal-dir-dedicated":"","member-dir":"/etcd/member","force-new-cluster":false,"heartbeat-interval":"100ms","election-timeout":"1s","initial-election-tick-advance":true,"snapshot-count":50000,"max-wals":5,"max-snapshots":5,"snapshot-catchup-entries":5000,"initial-advertise-peer-urls":["http://localhost:2380"],"listen-peer-urls":["http://localhost:2380"],"advertise-client-urls":["http://127.0.0.1:2379"],"listen-client-urls":["http://0.0.0.0:2379"],"listen-metrics-urls":[],"cors":["*"],"host-whitelist":["*"],"initial-cluster":"default=http://localhost:2380","initial-cluster-state":"new","initial-cluster-token":"etcd-cluster","quota-backend-bytes":4294967296,"max-request-bytes":1572864,"max-concurrent-streams":4294967295,"pre-vote":true,"initial-corrupt-check":false,"corrupt-check-time-interval":"0s","compact-check-time-enabled":false,"compact-check-time-interval":"1m0s","auto-compaction-mode":"revision","auto-compaction-retention":"1µs","auto-compaction-interval":"1µs","discovery-url":"","discovery-proxy":"","downgrade-check-interval":"5s"}
--- [ SNIP ] ---
milvus-minio | MinIO Object Storage Server
milvus-minio | Copyright: 2015-2023 MinIO, Inc.
milvus-minio | License: GNU AGPLv3 <https://www.gnu.org/licenses/agpl-3.0.html>
milvus-minio | Version: RELEASE.2023-09-30T07-02-29Z (go1.21.1 linux/amd64)
milvus-minio |
milvus-minio | Status: 1 Online, 0 Offline.
milvus-minio | S3-API: http://172.18.0.3:9000 http://127.0.0.1:9000
milvus-minio | Console: http://172.18.0.3:34531 http://127.0.0.1:34531
milvus-minio |
milvus-minio | Documentation: https://min.io/docs/minio/linux/index.html
--- [ SNIP ] ---
milvus-standalone | __ _________ _ ____ ______
milvus-standalone | / |/ / _/ /| | / / / / / __/
milvus-standalone | / /|_/ // // /_| |/ / /_/ /\ \
milvus-standalone | /_/ /_/___/____/___/\____/___/
milvus-standalone |
milvus-standalone | Welcome to use Milvus!
milvus-standalone | Version: v2.3.1
milvus-standalone | Built: Fri Sep 22 11:37:42 UTC 2023
milvus-standalone | GitCommit: 70cf65b05
milvus-standalone | GoVersion: go version go1.20.7 linux/amd64
milvus-standalone |
milvus-standalone | open pid file: /tmp/milvus/standalone.pid
milvus-standalone | lock pid file: /tmp/milvus/standalone.pid
milvus-standalone | [2023/10/07 16:45:33.038 +00:00] [INFO] [roles/roles.go:294] ["starting running Milvus components"]
milvus-standalone | [2023/10/07 16:45:33.039 +00:00] [INFO] [roles/roles.go:164] ["Enable Jemalloc"] ["Jemalloc Path"=/milvus/lib/libjemalloc.so]
milvus-standalone | [2023/10/07 16:45:33.043 +00:00] [INFO] [config/refresher.go:66] ["start refreshing configurations"] [source=FileSource]
milvus-standalone | [2023/10/07 16:45:33.043 +00:00] [DEBUG] [config/etcd_source.go:49] ["init etcd source"] [etcdInfo="{\"UseEmbed\":false,\"UseSSL\":false,\"Endpoints\":[\"etcd:2379\"],\"KeyPrefix\":\"by-dev\",\"CertFile\":\"/path/to/etcd-client.pem\",\"KeyFile\":\"/path/to/etcd-client-key.pem\",\"CaCertFile\":\"/path/to/ca.pem\",\"MinVersion\":\"1.3\",\"RefreshInterval\":5000000000}"]
--- [ SNIP ] ---
milvus-standalone | [2023/10/07 16:45:42.228 +00:00] [INFO] [gc/gc_tuner.go:90] ["GC Tune done"] ["previous GOGC"=100] ["heapuse "=30] ["total memory"=4528] ["next GC"=42] ["new GOGC"=200] [gc-pause=133.429µs] [gc-pause-end=1696697142228228341]
To check if all the necessary docker containers are up and running, execute the following command in another terminal window:
$ docker ps
The following would be the typical output:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f9613aae4eb0 milvusdb/milvus:v2.3.1 "/tini -- milvus run..." 2 minutes ago Up 2 minutes 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp, 0.0.0.0:19530->19530/tcp, :::19530->19530/tcp milvus-standalone 68516a50772f minio/minio:RELEASE.2023-09-30T07-02-29Z "/usr/bin/docker-ent..." 2 minutes ago Up 2 minutes (healthy) 9000/tcp milvus-minio 627a9207610e quay.io/coreos/etcd:v3.5.9 "etcd -advertise-cli..." 2 minutes ago Up 2 minutes 2379-2380/tcp milvus-etcd
For the hands-on demonstration, we will create a simple, pipe-delimited, news snippets file that contains the category and summary of a news item. Once the new items are inserted into Milvus, we will search for similar new items given a particular news item.
The following is the simple news snippets file located in the directory $MILVUS_HOME:
101|Business|Government shutdown, labor strikes will likely weigh on US consumers attitudes 102|Business|Stocks Suffer Worst Quarter Of 2023 As Good Vibes Dry Out 103|Business|China's economy stabilises, factory activity returns to expansion 104|Food|Frozen fruit recalled due to possible listeria outbreak 105|Food|Trader Joe's has had multiple food recalls recently 106|Health|COVID-19 linked to more sepsis cases than previously thought 107|Health|Parasitic worm that can enter brain was found in Atlanta 108|Health|As Covid infections rise, nursing homes are still waiting for vaccines 109|Health|Drinking too much water, also known as water intoxication can be deadly 110|Health|Virginia is experiencing a statewide outbreak of meningococcal disease 111|Technology|Apple will issue a software update to address iPhone 15 overheating complaints 112|Technology|Blend uses generative AI to give you a personalized clothing guide 113|Technology|Supermicro CEO predicts 20 percent of datacenters will adopt liquid cooling 114|Technology|Microsoft is planning to use nuclear energy to power its AI data centers 115|Technology|Amazon to Invest Up to $4 Billion in AI Startup Anthropic 116|Technology|Raspberry Pi 5 unveiled with a faster CPU and GPU along with other major upgrades 117|Travel|Shrek's 'swamp' now available to rent on Airbnb 118|Travel|Plane takes off with passengers but not a single checked bag on board 119|Travel|Luxury cruise ship freed after running aground in a Greenland fjord 120|Weather|New York declared a state of emergency due to extreme rainfall and flooding 121|Weather|Moroccans rally after devastating earthquake caused widespread destruction of lives, villages, and cultural sites 122|Weather|More than 5,000 presumed dead in Libya after catastrophic flooding breaks dams and sweeps away homes 123|Weather|Typhoon Haikui slams into Taiwan, disrupting work, classes and travel
To perform a similarity search, we need to store the embedded vector of the news item in a Milvus database Collection. This is where the pre-trained GloVe word embeddings come in handy.
To initialize and load the pre-trained GloVe word embeddings, execute the following code snippet:
from gensim.models import KeyedVectors glove_6B_200d = os.path.join(milvus_home, 'glove/glove.6B.200d.txt') w2v_model = KeyedVectors.load_word2vec_format(glove_6B_200d, binary=False, no_header=True)
To connect to the standalone Milvus instance, execute the following code snippet:
from pymilvus import connections db_alias = 'default' connections.connect(alias=db_alias, host='localhost', port='19530')
To create a new database in Milvus, execute the following code snippet:
from pymilvus import db db_name = 'mytest' db.create_database(db_name)
To create a Collection in our Milvus database, execute the following code snippet:
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
def create_collection(alias, collection_name):
def_news_category = 'General'
# Define the fields of the schema
news_id = FieldSchema(
name='news_id',
dtype=DataType.INT64,
is_primary=True
)
news_category = FieldSchema(
name='news_category',
dtype=DataType.VARCHAR,
max_length=15,
default_value=def_news_category
)
news_snippet_text = FieldSchema(
name='news_snippet_text',
dtype=DataType.VARCHAR,
max_length=256
)
news_snippet_vector = FieldSchema(
name='news_snippet_vector',
dtype=DataType.FLOAT_VECTOR,
dim=200
)
# Define the collection
collection_schema = CollectionSchema(
fields=[news_id, news_category, news_snippet_text, news_snippet_vector],
description="News Snippet Search",
enable_dynamic_field=True
)
# Create the collection
collection = Collection(
name=collection_name,
schema=collection_schema,
using=alias
)
# Return the collection
return collection
db.using_database(db_name)
db_collection = 'news_snippets'
collection = create_collection(db_alias, db_collection)
Notice in the code snippet above, that in order to create a Collection in our Milvus database, one needs to define the schema for the Collection.
Also, notice that we have a field for the vector embedding called news_snippet_vector with a data type of DataType.FLOAT_VECTOR.
To create an index on the field news_snippet_vector, execute the following code snippet:
def create_index(field, collection):
index_params = {
'metric_type': 'L2',
'index_type': 'IVF_FLAT',
'params': {'nlist': 128}
}
collection.create_index(field, index_params)
field_name = 'news_snippet_vector'
create_index(field_name, collection)
Notice in the code snippet above, we are using the Euclidean Distance (option L2) when creating the index.
To insert each of the new snippet items into our Collection in the Milvus database, execute the following code snippet:
def get_new_snippets(filename):
with open(filename) as file:
lines = [line.split('|') for line in file]
return lines
new_snippets_file = os.path.join(milvus_home, 'news-snippets.txt')
ns_lines = get_new_snippets(new_snippets_file)
def get_sentence_embedding(sentence, tokenizer, model):
tokens = tokenizer.tokenize(sentence)
words = [word.lower() for word in tokens if word.isalpha()]
embedding = model.get_mean_vector(words)
return embedding
id_106 = '106'
vec_106 = None
id_112 = '112'
vec_112 = None
for line in ns_lines:
embedding = get_sentence_embedding(line[2].strip(), tokenizer, model)
item = [[int(line[0])], [line[1]], [line[2]], [embedding]]
if line[0] == id_106:
vec_106 = embedding
if line[0] == id_112:
vec_112 = embedding
collection.insert(item)
collection.flush()
Notice in the above code snippet that we are getting the mean vector embedding for each of the news item sentences. This is a simple approximation approach for finding the embedding of a document (the senetence in this case).
To search for new snippets similar to the news snippet with id 106, execute the following code snippet:
collection.load()
results = search_collection(field_name, vec_106, collection)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'---> {res}')
Note that Milvus performs a similarity search in-memory. In order to bring the data for a given Collection to memory, one needs to invoke the collection.load() operation.
The following is the complete Python code which performs all the basic operations on our Milvus instance:
#
# @Author: Bhaskar S
# @Blog: https://www.polarsparc.com
# @Date: 07 Oct 2023
#
import os
from gensim.models import KeyedVectors
from nltk.tokenize import WordPunctTokenizer
from pymilvus import connections, db
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
def get_new_snippets(filename):
with open(filename) as file:
lines = [line.split('|') for line in file]
return lines
def init_embedding_model(filename):
w2v_model = KeyedVectors.load_word2vec_format(filename, binary=False, no_header=True)
return w2v_model
# Function to return the vector embedding for a given sentence
def get_sentence_embedding(sentence, tokenizer, model):
tokens = tokenizer.tokenize(sentence)
words = [word.lower() for word in tokens if word.isalpha()]
embedding = model.get_mean_vector(words)
return embedding
# Function to create a Milvus collection
def create_collection(alias, collection_name):
def_news_category = 'General'
# Define the fields of the schema
news_id = FieldSchema(
name='news_id',
dtype=DataType.INT64,
is_primary=True
)
news_category = FieldSchema(
name='news_category',
dtype=DataType.VARCHAR,
max_length=15,
default_value=def_news_category
)
news_snippet_text = FieldSchema(
name='news_snippet_text',
dtype=DataType.VARCHAR,
max_length=256
)
news_snippet_vector = FieldSchema(
name='news_snippet_vector',
dtype=DataType.FLOAT_VECTOR,
dim=200
)
# Define the collection
collection_schema = CollectionSchema(
fields=[news_id, news_category, news_snippet_text, news_snippet_vector],
description="News Snippet Search",
enable_dynamic_field=True
)
# Create the collection
collection = Collection(
name=collection_name,
schema=collection_schema,
using=alias
)
# Return the collection
return collection
# Function to create an index on the specified field of the given collection
def create_index(field, collection):
index_params = {
'metric_type': 'L2',
'index_type': 'IVF_FLAT',
'params': {'nlist': 128}
}
collection.create_index(field, index_params)
# Function that performs a Similarity search on the given collection
def search_collection(field, vector, collection, limit=3):
search_params = {
'data': [vector],
'anns_field': field,
'limit': limit,
'param': {'metric_type': 'L2'}
}
results = collection.search(**search_params)
return results
# Main function
def main():
milvus_home = os.getenv('MILVUS_HOME')
print(f'milvus_home: {milvus_home}')
glove_6B_200d = os.path.join(milvus_home, 'glove/glove.6B.200d.txt')
print(f'glove_6B_200d: {glove_6B_200d}')
print(f'+++ Initializing {glove_6B_200d} embedding model')
model = init_embedding_model(glove_6B_200d)
tokenizer = WordPunctTokenizer()
new_snippets_file = os.path.join(milvus_home, 'news-snippets.txt')
print(f'+++ Reading news snippets from {new_snippets_file}')
ns_lines = get_new_snippets(new_snippets_file)
db_alias = 'default'
db_name = 'mytest'
db_collection = 'news_snippets'
print(f'+++ Connecting to the standalone Milvus Vector DB')
connections.connect(alias=db_alias, host='localhost', port='19530')
db_list = db.list_database()
print(f'+++ List of databases (before) - {db_list}')
print(f'+++ Creating the DB - {db_name}')
db.create_database(db_name)
db_list = db.list_database()
print(f'+++ List of databases (after) - {db_list}')
print(f'+++ Using the DB - {db_name}')
db.using_database(db_name)
print(f'+++ Creating collection - {db_collection}')
collection = create_collection(db_alias, db_collection)
print(f'+++ Number of entries in collection {db_collection}: {collection.num_entities}')
field_name = 'news_snippet_vector'
print(f'+++ Creating index on collection {db_collection} for field: {field_name}')
create_index(field_name, collection)
id_106 = '106'
vec_106 = None
id_112 = '112'
vec_112 = None
print(f'+++ Inserting news snippets into collection {db_collection}')
for line in ns_lines:
embedding = get_sentence_embedding(line[2].strip(), tokenizer, model)
item = [[int(line[0])], [line[1]], [line[2]], [embedding]]
if line[0] == id_106:
vec_106 = embedding
if line[0] == id_112:
vec_112 = embedding
collection.insert(item)
collection.flush()
print(f'+++ Number of entries in collection {db_collection}: {collection.num_entities}')
print(f'+++ [1] Loading collection {db_collection} to memory')
collection.load()
print(f'+++ Searching Health news snippets similar to #106 from collection {db_collection}')
results = search_collection(field_name, vec_106, collection)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'[1] ---> {res}')
print(f'+++ [1] Searching Technology news snippets similar to #112 from collection {db_collection}')
results = search_collection(field_name, vec_112, collection)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'---> {res}')
print(f'+++ [1] Upserting #124 dummy news snippets into collection {db_collection}')
line_1 = 'No interesting Tech news'
embedding_1 = get_sentence_embedding(line_1, tokenizer, model)
item = [[124], ['Technology'], [line_1], [embedding_1]]
collection.upsert(item)
collection.flush()
print(f'+++ [2] Loading collection {db_collection} to memory')
collection.load()
print(f'+++ [2] Searching Technology news snippets similar to #112 from collection {db_collection}')
results = search_collection(field_name, vec_112, collection, limit=5)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'[2] ---> {res}')
print(f'+++ [2] Upserting #124 real news snippets in collection {db_collection}')
line_2 = 'Amazon to Invest resources in its AI Platform'
embedding_2 = get_sentence_embedding(line_2, tokenizer, model)
item = [[124], ['Technology'], [line_2], [embedding_2]]
collection.upsert(item)
collection.flush()
print(f'+++ [3] Loading collection {db_collection} to memory')
collection.load()
print(f'+++ [3] Searching Technology news snippets similar to #112 from collection {db_collection}')
results = search_collection(field_name, vec_112, collection, limit=5)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'[3] ---> {res}')
print(f'+++ Deleting #124 news snippets from collection {db_collection}')
expr = 'news_id in [124]'
collection.delete(expr)
collection.flush()
print(f'+++ [4] Searching Technology news snippets similar to #112 from collection {db_collection}')
results = search_collection(field_name, vec_112, collection)
for i, result in enumerate(results):
for j, res in enumerate(result):
print(f'[4] ---> {res}')
print(f'--- Releasing collection {db_collection} from memory')
collection.release()
print(f'--- Dropping index for collection {db_collection}')
collection.drop_index()
print(f'--- Dropping collection {db_collection}')
collection.drop()
print(f'--- Dropping the DB - {db_name}')
db.drop_database(db_name)
print(f'--- Disconnecting from the standalone Milvus Vector DB')
connections.disconnect(db_alias)
if __name__ == '__main__':
main()
Executing the above Python code generates the following would be the typical output:
milvus_home: /home/alice/milvus
glove_6B_200d: /home/alice/milvus/glove/glove.6B.200d.txt
+++ Initializing /home/alice/milvus/glove/glove.6B.200d.txt embedding model
+++ Reading news snippets from /home/alice/milvus/news-snippets.txt
+++ Connecting to the standalone Milvus Vector DB
+++ List of databases (before) - ['default']
+++ Creating the DB - mytest
+++ List of databases (after) - ['default', 'mytest']
+++ Using the DB - mytest
+++ Creating collection - news_snippets
+++ Number of entries in collection news_snippets: 0
+++ Creating index on collection news_snippets for field: news_snippet_vector
+++ Inserting news snippets into collection news_snippets
+++ Number of entries in collection news_snippets: 23
+++ [1] Loading collection news_snippets to memory
+++ Searching Health news snippets similar to #106 from collection news_snippets
[1] ---> id: 106, distance: 0.0, entity: {}
[1] ---> id: 108, distance: 0.1292576789855957, entity: {}
[1] ---> id: 107, distance: 0.14604675769805908, entity: {}
+++ [1] Searching Technology news snippets similar to #112 from collection news_snippets
---> id: 112, distance: 0.0, entity: {}
---> id: 114, distance: 0.15123721957206726, entity: {}
---> id: 115, distance: 0.16058120131492615, entity: {}
+++ [1] Upserting #124 dummy news snippets into collection news_snippets
+++ [2] Loading collection news_snippets to memory
+++ [2] Searching Technology news snippets similar to #112 from collection news_snippets
[2] ---> id: 112, distance: 0.0, entity: {}
[2] ---> id: 114, distance: 0.15123721957206726, entity: {}
[2] ---> id: 115, distance: 0.16058120131492615, entity: {}
[2] ---> id: 117, distance: 0.164011150598526, entity: {}
[2] ---> id: 116, distance: 0.18734167516231537, entity: {}
+++ [2] Upserting #124 real news snippets in collection news_snippets
+++ [3] Loading collection news_snippets to memory
+++ [3] Searching Technology news snippets similar to #112 from collection news_snippets
[3] ---> id: 112, distance: 0.0, entity: {}
[3] ---> id: 114, distance: 0.15123721957206726, entity: {}
[3] ---> id: 115, distance: 0.16058120131492615, entity: {}
[3] ---> id: 117, distance: 0.164011150598526, entity: {}
[3] ---> id: 124, distance: 0.17247149348258972, entity: {}
+++ Deleting #124 news snippets from collection news_snippets
+++ [4] Searching Technology news snippets similar to #112 from collection news_snippets
[4] ---> id: 112, distance: 0.0, entity: {}
[4] ---> id: 114, distance: 0.15123721957206726, entity: {}
[4] ---> id: 115, distance: 0.16058120131492615, entity: {}
--- Releasing collection news_snippets from memory
--- Dropping index for collection news_snippets
--- Dropping collection news_snippets
--- Dropping the DB - mytest
--- Disconnecting from the standalone Milvus Vector DB
Interestingly enough the Milvus similarity searches seem to produce quite accurate results.
References