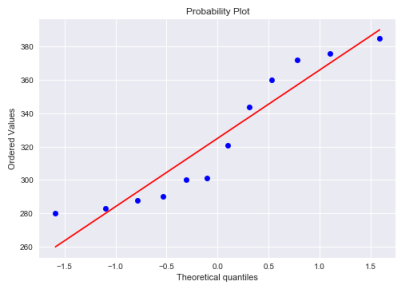
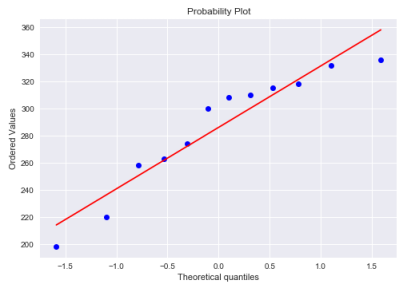
The two sample sizes are \(n_1 = 15\) and \(n_2 = 14\). Given sample sizes are \(\lt 30\), so we need to determine if the two samples are normally distributed.
One can use the Q-Q plot to determine a a data set is normally distributed. A Q-Q (short for 'quantile-quantile') plot is often used to determine whether or not a set of data follows a normal distribution. The x-axis of the Q-Q plot displays the theoretical quantiles, while the y-axis of the Q-Q plot displays the actual data set. If the data values fall along a roughly straight line at a 45-degree angle, then the data is normally distributed.
The following illustration shows the distribution of the heights for the first group consisting of Italian nationality:
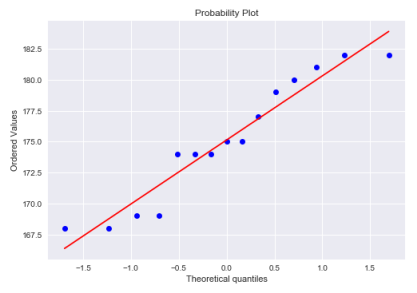
The distribution for the first group consisting of Italian nationality is almost normal.
The following illustration shows the distribution of the heights for the second group consisting of German nationality:
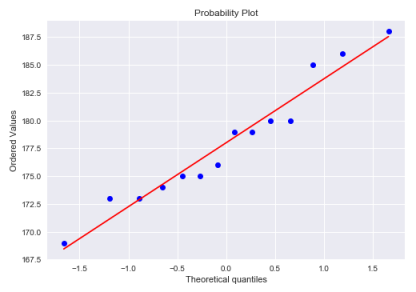
The distribution for the second group consisting of German nationality is almost normal.
The sample mean \(\bar{x_1}\) for the first group is computed by adding all the sample heights of the Italians and dividing by \(n_1 = 15\). That is, \(\bar{x_1} \approx 175.13\).
The sample mean \(\bar{x_2}\) for the second group is computed by adding all the sample heights of the Germans and dividing by \(n_2 = 14\). That is, \(\bar{x_2} = 178.0\).
Null hypothesis: \(H_0: \mu_1 = \mu_2\)
Alternate hypothesis: \(H_a: \mu_1 \ne \mu_2\)
In this situation, the hypothesis test is deciding if there is a difference between the mean heights of the two groups. Hence, this is a two-tailed test.
Given the confidence level \(c = 95\%\), significance level \(\alpha = (1 - c) = 0.05\). Also, given are the population standard deviation of the two groups \(\sigma_1 = 5\) and \(\sigma_2 = 6.5\) respectively.
We know \(\sigma_{\bar{x_1}-\bar{x_2}}\) = \(\Large{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}}\) = \(\Large{\sqrt{\frac{5^2}{15} + \frac{6.5^2}{14}}}\) \(\approx 2.164\).
Also, we know z = \(\Large{\frac{\bar{x_1} - \bar{x_2}}{\sigma_{\bar{x_1}-\bar{x_2}}}}\) = \(\Large{\frac{175.13 - 178.0}{2.164}}\) \(\approx\) -1.324.
For \(\alpha = 0.05\), the critical values from the z-table for -0.025 and 0.025 (since it is a two-tailed test) are \(z_c = -1.96\) and \(z_c = 1.96\).
Since the computed standardized test statistic (z) is below the critical values \(z_c = -1.96\), we FAIL to reject the null hypotesis \(H_0\).
Therefore, with the \(95\%\) confidence level, we conclude that the means heights of the two groups are NOT significantly different.
One could also use the p-value to compare against the significance level \(\alpha\) to make a decision. The p-value corresponding to the test statistic z = -1.324 (from the z-table) is \(\approx 0.0927\). Since this is a two-tailed test, the p-value is 2 times the probability, which is \(\approx 0.1853\). Since the p-value is greater than \(\alpha = 0.05\), we FAIL to reject the null hypotesis \(H_0\).